Then I ingest raw data using:
"
LOGFILE=$LOGDIR/ingest_science_202102.log;
SCIFILES=M81/object/*.fits;
date | tee $LOGFILE;
butler ingest-raws $REPO $SCIFILES --transfer link
2>&1 | tee -a $LOGFILE;
date | tee -a $LOGFILE
"
And I check the data:
(lsst-scipipe-3.0.0) [yyb@raku LSST]$ butler query-dimension-records $REPO exposure \
–where “instrument=‘HSC’ AND exposure.observation_type=‘science’”
WARNING: version mismatch between CFITSIO header (v4.000999999999999) and linked library (v4.01).
WARNING: version mismatch between CFITSIO header (v4.000999999999999) and linked library (v4.01).
WARNING: version mismatch between CFITSIO header (v4.000999999999999) and linked library (v4.01).
Note that butler --log-file my.log ingest-raws will store the logs in a file for you (and use JSON format if you use .json). All the butler commands support that. See butler --help.
Can you obtain a master bias and flat? Or the relevant raw files from which you can build them?
@SherlockYibo Can you try to download the biases, darks, flats and fringes from HSC calibration data set — hsc-calib 1.0.0 documentation by looking at dates close to the dates of your observations. NAOJ has these calibration data processed with HSCPipe8.4 and I have been using them with LSST pipelines for my processing and did not have much trouble.
The way I would do this is to first setup a gen2 repository ingest the calibs into this repository and then convert it using butler convert but perhaps there are better ways to do this.
# Create gen2 repo
GEN2REPO=/work/surhud.more/gen2_repo
echo lsst.obs.hsc.HscMapper > $GEN2REPO/_mapper
cd $GEN2REPO
mkdir calibrations_from_naoj
cd calibrations_from_naoj
#wget calibrations
cd ..
# Install Brighter fatter kernel
mkdir -p $GEN2REPO/CALIB/BFKERNEL
cd $GEN2REPO/CALIB/BFKERNEL
ln -s $OBS_SUBARU_DIR/hsc/brighter_fatter_kernel.pkl
# Install transmission curves
installTransmissionCurves.py $GEN2REPO
# Ingest at least one visit
ingestImages.py $GEN2REPO /work/surhud.more/Subaru_raw/*000442*fits --mode=link
ingestImages.py $GEN2REPO /work/surhud.more/Subaru_raw/*000443*fits --mode=link
# Ingest curated calibrations
ingestCuratedCalibs.py $GEN2REPO --calib $GEN2REPO/CALIB $OBS_SUBARU_DATA_DIR/hsc/defects
# Ingest calibrations from
ingestCalibs.py $GEN2REPO --calib=$GEN2REPO/CALIB calibrations_from_naoj/*/*/*/*fits --validity 365
The next release of science pipelines is not going to have gen2 in it.
What you can do is use butler ingest-files – you have to define the dataId for each file in a CSV file and then run it for each dataset type. Then when the calibrations are in you can run butler certify-calibrations to define the validity ranges.
You’ll want to use bias (all lowercase) as the dataset type name and ExposureF as the storage class name when registering the dataset type. I’ll explain more when I get into the office, but the short answer is that the set of allowed storage classes is mostly predefined, and “SimpleCatalog” is one of them while “Bias” is not.
Oh, and you’ll need to use detector as the only dimension when registering the dataset type (analogous to htm7 for the reference catalog registration).
Could I please encourage you to copy and paste the text of your commands and output, rather than using screenshots? Text is easily indexed and searchable, allowing you and others to find answers based on error messages and commands in the future.
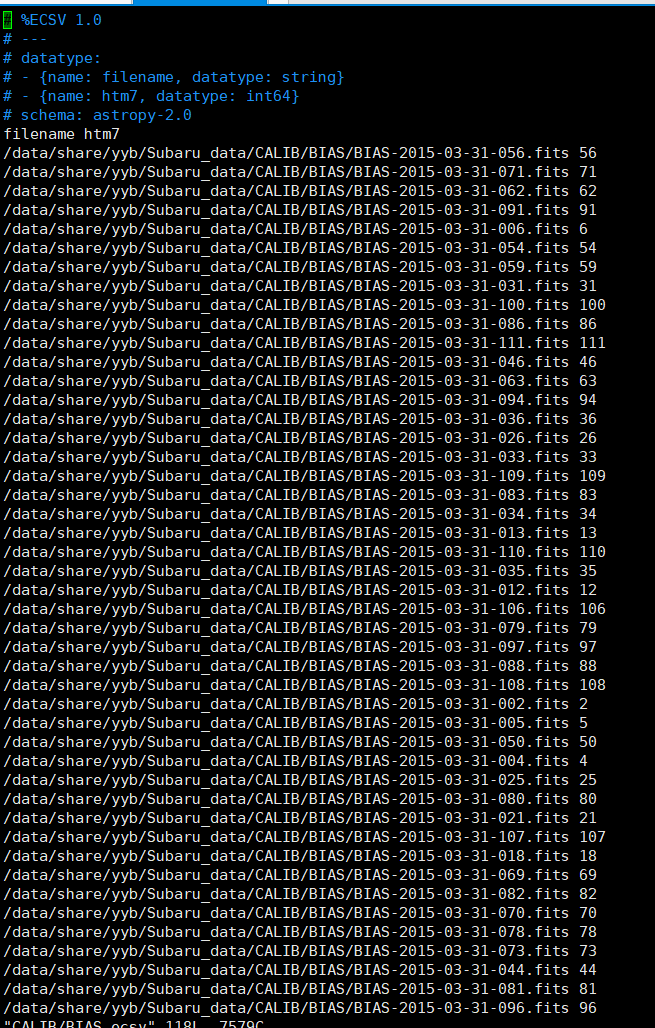
This is my code of writing Bias.ecsv file, and it’s a kind of copy the refcats.ecsv
import os
import glob
import astropy.table
outdir = "/data/share/yyb/Subaru_data/CALIB"
bias = "/data/share/yyb/Subaru_data/CALIB/BIAS"
calib_dirs = [bias]
for calib_dir in calib_dirs:
outfile = f"{outdir}/{os.path.basename(calib_dir)}.ecsv"
print(f"Saving to: {outfile}")
table = astropy.table.Table(names=("filename", "htm7"), dtype=("str", "int"))
files = glob.glob(f"{calib_dir}/*.fits")
for ii, file in enumerate(files):
print(f"{ii}/{len(files)} ({100*ii/len(files):0.1f}%)", end="\r")
try:
file_index =int(os.path.basename(os.path.splitext(file)[0])[-3:])
table.add_row((file, file_index))
except ValueError:
continue
table.write(outfile,overwrite=True)
## This is how I create astropy-readable .ecsv
# output directory to save .ecsv files
outdir = '/data/share/yyb/lsst_stack/refcats'
# full paths to LSST sharded reference catalogues
gaiadr2 = '/data/share/yyb/lsst_stack/refcats/gaia_dr2_20200414'
panstarrsps1 = '/data/share/yyb/lsst_stack/refcats/ps1_pv3_3pi_20170110'
refcat_dirs = [gaiadr2,panstarrsps1]
# loop over each FITS file in all refcats
# note: this constructs a series of .ecsv files, each containing two columns:
# 1) the FITS filename, and 2) the htm7 pixel index
for refcat_dir in refcat_dirs:
outfile = f"{outdir}/{os.path.basename(refcat_dir)}.ecsv"
print(f"Saving to: {outfile}")
table = astropy.table.Table(names=("filename", "htm7"), dtype=("str", "int"))
files = glob.glob(f"{refcat_dir}/[0-9]*.fits")
print(len(files))
for ii, file in enumerate(files):
print(f"{ii}/{len(files)} ({100*ii/len(files):0.1f}%)", end="\r")
# try/except to catch extra .fits files which may be in this dir
try:
file_index = int(os.path.basename(os.path.splitext(file)[0]))
except ValueError:
continue
else:
table.add_row((file, file_index))
table.write(outfile,overwrite= True)
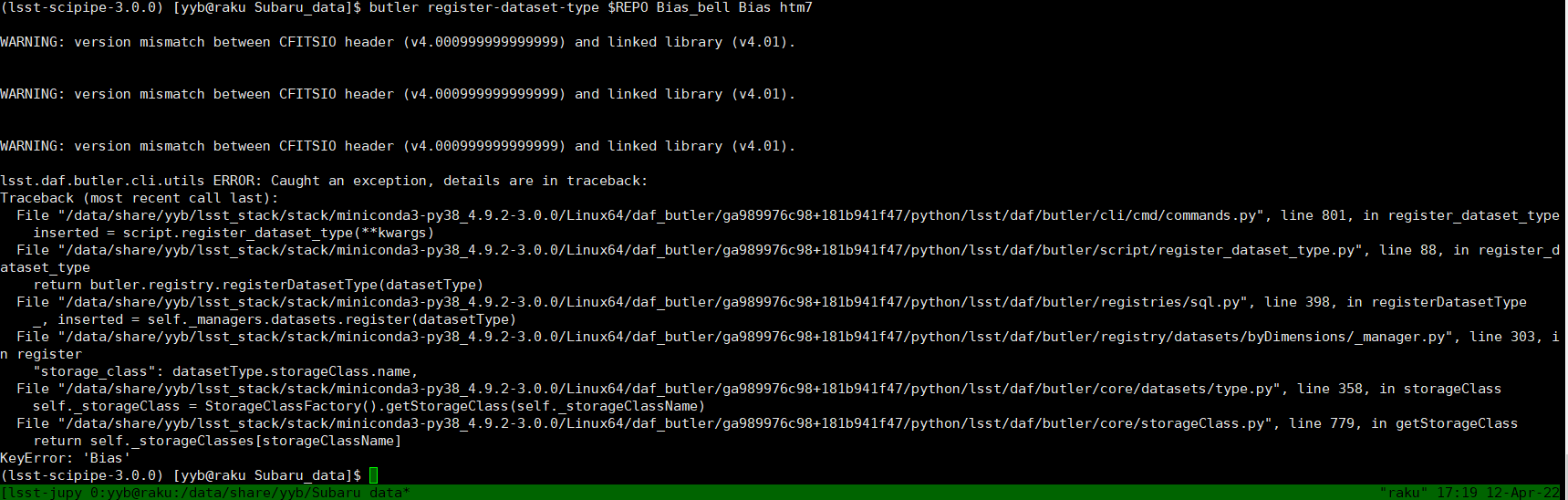
u means that I should instead htm7 with detector? like this:
lsst.daf.butler.cli.utils ERROR: Caught an exception, details are in traceback:
Traceback (most recent call last):
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/cli/cmd/commands.py", line 801, in register_dataset_type
inserted = script.register_dataset_type(**kwargs)
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/script/register_dataset_type.py", line 88, in register_dataset_type
return butler.registry.registerDatasetType(datasetType)
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/registries/sql.py", line 398, in registerDatasetType
_, inserted = self._managers.datasets.register(datasetType)
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/registry/datasets/byDimensions/_manager.py", line 303, in register
"storage_class": datasetType.storageClass.name,
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/core/datasets/type.py", line 358, in storageClass
self._storageClass = StorageClassFactory().getStorageClass(self._storageClassName)
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/core/storageClass.py", line 779, in getStorageClass
return self._storageClasses[storageClassName]
KeyError: 'Bias'
See the help text, available from butler register-dataset-type --help. Putting that and @jbosch’s directions together, I think you should try butler register-dataset-type $REPO bias ExposureF detector.
butler ingest-files [OPTIONS] REPO DATASET_TYPE RUN TABLE_FILE
So I run command and got error:
(lsst-scipipe-3.0.0) [yyb@raku repo]$ butler ingest-files -t link $REPO Bias HSC/calib /data/share/yyb/Subaru_data/CALIB/BIAS.ecsv
lsst.daf.butler.cli.utils ERROR: Caught an exception, details are in traceback:
Traceback (most recent call last):
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/core/dimensions/_coordinate.py", line 24 8, in standardize
values = tuple(d[name] for name in graph.required.names)
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/core/dimensions/_coordinate.py", line 24 8, in <genexpr>
values = tuple(d[name] for name in graph.required.names)
KeyError: 'instrument'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/cli/cmd/commands.py", line 771, in inges t_files
script.ingest_files(**kwargs)
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/script/ingest_files.py", line 113, in intgest_files
datasets = extract_datasets_from_table(table, common_data_id, datasetType, formatter, prefix)
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/script/ingest_files.py", line 172, in ex tract_datasets_from_table
ref = DatasetRef(datasetType, dataId) # type: ignore
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/core/datasets/ref.py", line 179, in __in it__
self.dataId = DataCoordinate.standardize(dataId, graph=datasetType.dimensions)
File "/data/share/yyb/lsst_stack/stack/miniconda3-py38_4.9.2-3.0.0/Linux64/daf_butler/ga989976c98+181b941f47/python/lsst/daf/butler/core/dimensions/_coordinate.py", line 2500, in standardize
raise KeyError(f"No value in data ID ({mapping}) for required dimension {err}.") from err
KeyError: "No value in data ID ({'htm7': 56}) for required dimension 'instrument'."
As u can see, here I use HSC/calib as RUN, this is because I thought these bias data belong to the part of calib. Please tell me what RUN stands for
Our convention is to call this dataset type bias not Bias.
A bias must be defined with dimensions instrument and detector not just detector. You need to then set that instrument to “DECam” (since it’s fixed you can use the --data-id option to ingest-files).
The RUN collection is anything you like but should not be a calibration collection. You can call it “DECam/master-biases/YYYYMMDD” for example (since presumably these biases are for some validity range). Then when you run butler certify-calibrations you would specify that RUN collection as the source.
In addition to @timj’s points, biases do not have an htm dimension. You need to rewrite your CSV file with the correct dimensions: instrument and detector.