I’ve been tasked with making an end user documentation tree for LDM-294. This message is to coordinate how this can be best integrated with the DM Product Tree.
For background, at the highest level, this is a map of what I see as the main end user documentation sub-sites for the DM system:
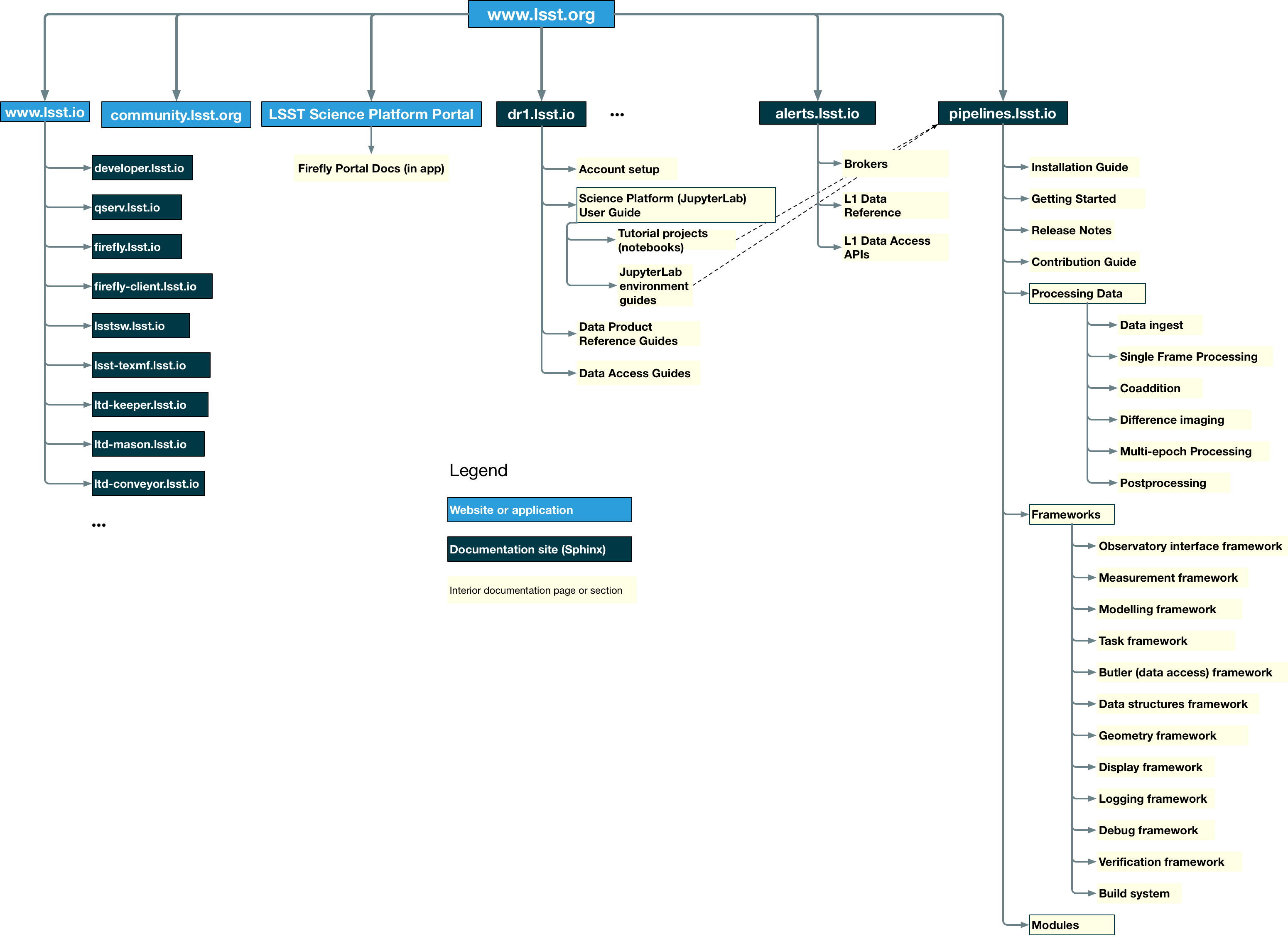
The key documentation sites I expect we’ll make for astronomers are:
-
pipelines.lsst.io: integrated documentation for our science pipeline stack. -
alerts.lsst.io: integrated documentation for the alert stream service. -
drN.lsst.io: integrated documentation for a specific L2 data release and data access services.
There are additional documentation sites for each software product and service that aren’t directly astronomer-facing. These include, Qserv, Firefly, DAX servers, and so on. These additional doc sites are tied to code bases, and are pitched to that product’s developers and operators. Every software repo will have a documentation site.
For the documentation tree, what I’d like to do is map each WBS to a software or service product and then to a documentation site, for example:

For many documentation sites we’ll have multiple software projects integrated into one documentation product (for example, each science pipelines package is integrated into pipelines.lsst.io).
Some products, particularly those for services like DAX and Qserv, will have their own documentation sites for developers and operators tied closely to the code base, in addition to being implicated in astronomer-facing documentation for DR or alert stream products:
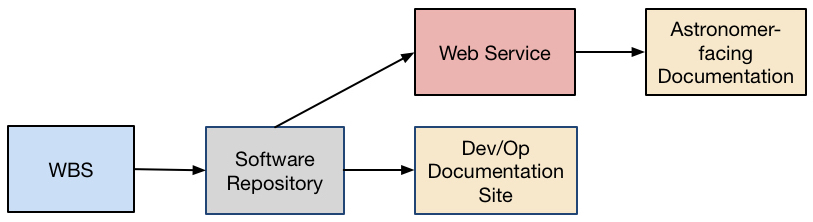
@ktl: I’d like to see how we can modify the Product Tree CSV to accommodate this mapping. I think the best way to do this is to add new CSV files with SQL-style foreign key relationships.
One is a softwareproducts.csv with one row per Git repository. The columns are:
- name (i.e. repo name in the GitHub URL)
- Git repo URL
- WBS (key into
productlist.csv)
(Effectively this replaces the “Package List” column in the product tree CSV
Then also add a webservices.csv table, with columns:
- service name
- software repo names (key into
softwareproducts.csv) - WBS (only if the web service is not associated with a software repo, otherwise the WBS automatically flows from the
softwareproducts.csvtable)
And finally add a docproducts.csv table with columns:
- site domain name
- root repository URL (e.g., of the Sphinx project)
- list of software repo and service names (keys into
softwareproducts.csvandwebservices.csv)
Then, if necessary, I can add additional tables that map documentation projects down to the section and page level, but that may be beyond the immediate scope of LDM-294 (we’re developing content architectures for documentation sites elsewhere, in https://dmtn-030.lsst.io, for example).
@ktl what do you think of this CSV refactor? @womullan, @timj, and @swinbank do you have any other input on how we’re capturing this product and documentation tree?
Another aspect is that this data model is a graph with some many-to-one relationships, rather than a tree. This might impact some of the Python visualization tools we have.