This post is just to summarize and give follow-up on a discussion this morning (2016-09-14) about the best way to document the FITS data model (see DM-4621).
My main take-aways from that discussion are, to roughly paraphrase:
- @jbosch: The FITS data model is something that we need to document internally for our own development, but it isn’t a stable public API. (All FITS interaction should currently be done through Stack code.)
- @timj noted that this is effectively an interface control document (ICD). However, @ktl and others pointed out that making this an ICD (and thus an LDM) would put too much process burden on both the TCT and developers.
- There’s a desire to keep this document versioned with the code. @jbosch suggests including the document in the code repo (that is,
afw). There was some discussion about whether this meant the document was part of theafwuser documentation (i.e., content in thedoc/directory). @timj wants to ensure that this document is directly citeable, rather than being a page in the user guide. - Working consensus seemed to be that the document should be a DM Technote (DMTN) and that it should be tagged with code versions.
- There was also a desire to separate the abstract data model from format-specific concerns (to enable both FITS and HDF5 serializations, for example).
(The HipChat participants can tell me if I didn’t capture the ideas correctly.)
I’m in the middle of drafting LDM-493: Data Management Documentation Architecture (no link yet) and its purpose will be to streamline discussions like this of ‘how do I document this?’
The following opinions thus reflect what I’m writing up in LDM-493, though of course they’re not change-controlled yet. So this discussion is a great opportunity to test LDM-493.
-
The
doc/directories of stack packages contribute to the Science Pipelines User Guide. User Guides are a class of documentation that we write primarily for our end-users (astronomers using LSST software and data, though there can also be user guides for internal customers; the DM Developer Guide is an example). Because User Guides are written specifically for users, we don’t want extraneous design and architectural documentation in the guides. Given that the FITS data model is currently a private API, we shouldn’t be including this information in the User Guide. Once it becomes a public API, the FITS data model should be part of the User Guide. -
We absolutely need to document our designs and architectures to enable efficient internal development. Design Documents (LDMs) are formal documentation of DM designs. As others also noted in the HipChat conversation, I’ve noticed that there’s hesitation to document too much in the LDM series because of the process overhead. Thus in LDM-493 I’m proposing a class of document called an Implementation Technical Note. These are just like Technotes in every way except:
- Implementation Technical Notes have metadata that traces to an LDM design document. I.e., an Implementation Technical Note is a document written and maintained at a level directly relevant to DM developers, yet exists within the scope agreed upon in an LDM document.
- Unlike regular Technical Notes, Implementation Technical Notes are expected to be maintained with the reality of the code base. For example, an Implementation Technical Note can start out as a design proposal. Once code is implemented and the original design changes, the Implementation Technical Note should be updated.
Implementation Technical Notes vs User Guides
Implementation Technical Notes are different from User Guides in that User Guides document how the public API should be used, whereas Implementation Technical Notes document the design and implementation details for developers. The two sides of documentation can link between each other. As our codebase matures and less development is actively occurring, information will naturally migrate into the user guide.
Implementation Technical Notes vs User Guides
Regular Technical Notes exist to document design proposals, experiments, and investigations not directly connected to the implementation of the Data Management System itself.
Documentation Architecture Visualized
The following diagram from the LDM-493 draft shows how these classes of documents fit together from an information flow perspective. Requirements flow into design documents and implementation technical notes for developers, which then flow to consumers in user guides.
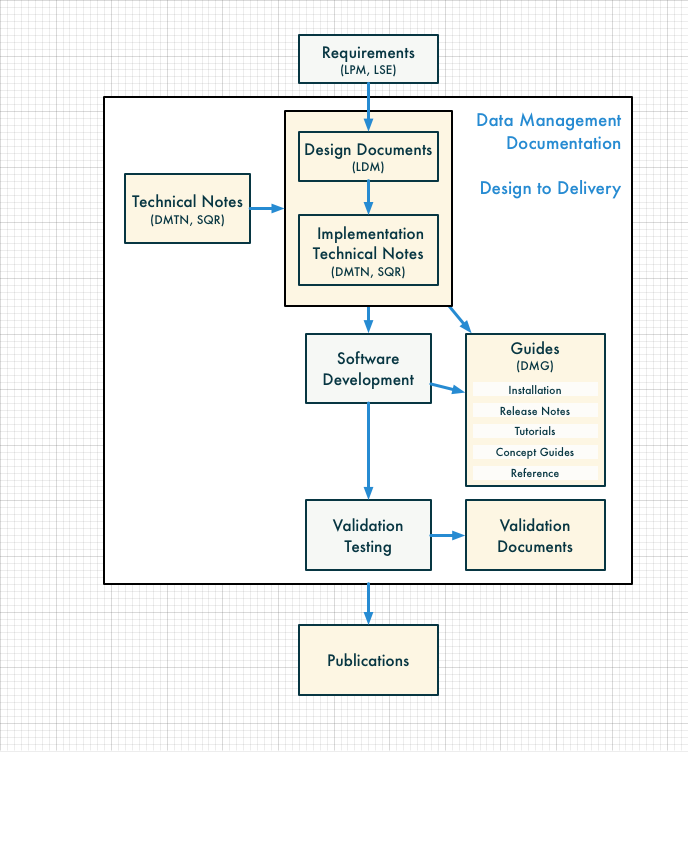
An Implementation Technical Note for the FITS data model
To answer @rowen’s original question, my opinion is that this FITS data model document should be an Implementation Technical Note describing the data model from a developer perspective to enable internal DM collaboration.
This technote can be made with the regular lsst-technote-bootstrap template. Since Implementation Technical Notes don’t formally exist, per se, the metadata treatment for them does not exist yet. This technote will have a DMTN serial number, just like other technotes.
There are two options for where to put such a technote:
- In its own repo, as we do for other technotes, or
- In a directory inside the code (
afw) repo, which makes it easier to connect the documentation to code inafw.
We’ve never done #2 before, but something like this has been requested by DESC. The caveats are:
- We’d need to add a
.travis.ymlto the root ofafwto enable Travis-based documentation builds. - We’d need to add a
technotes/directory to the root ofafwto host such implementation technotes. - I’d need to adapt ltd-mason to only build the technote when the technote itself has changed, not for every ticket branch.
There was some discussion on HipChat about doing #1, but making the technote a Git submodule in afw. I’m not sure this would work since its only the branches and tags in the technote repo itself that matter to LSST the Docs. If we do #1, I think we’d just tag the repo with each version of the code base, and use branches from afw tickets (i.e., an afw ticket that touches the FITS data model must update both the technote repo and afw itself.).
I welcome feedback on whether #1 or #2 is preferable.
Of course, I also welcome feedback on the concept of Implementation Technical Notes as a class of DM documentation.
