At the brokers meeting in Garching on 25 Jan, there was some talk of a standard API for brokers, to request information about an object or make a cone search. But perhaps we can go further, and think of an ecosystem of kafka streams? We should be streaming, not requesting! Producers and consumers communicate by Kafka. LSST and ZTF are pure producers. Brokers act as filters that consume and then produce. Each stream would contain messages, each message with a key – the objectId – and a data payload. A stream can be a live-feed, or can be generated at will from a database query.
To kick this off, we would need:
Formatting agreement, perhaps AVRO or JSON, and how to extract the objectId and payload from the message
A registry of objectId namespaces, examples are LSST:dia, LSST:ss, and ZTF
A registry of kafka-server names (consumers and filters), with the Kafka topics they support, and how to authenticate
This makes it easy to add new producers to a broker (eg. LS4). We can imagine a number of types of filters: to classify the alert, do a crossmatch, or find parameters for a fit to a lightcurve. The idea of querying a database is what we learned in 2000, now we learn to work with streams.
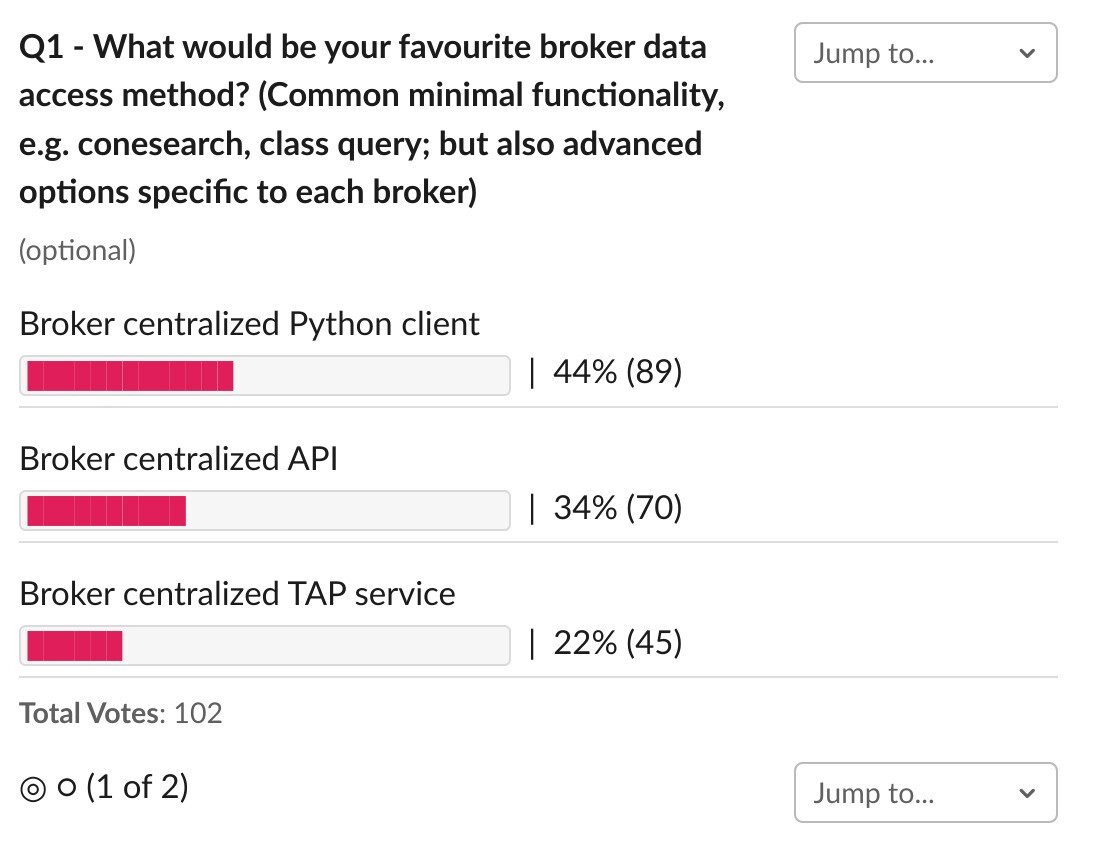
Thanks for bringing this. I agree that we will need something like this eventually, but I think that we should first get users on board using brokers and then we can offer more stream-like services. We need to strike a balance between what brokers believe users will need and what users declare they need. In the conference, users were requesting more information about how to use brokers and simple data access tools. To understand this requirement better we made a quick poll among the conference attendees and the most voted options for data access and documentation were a simple python client and jupyter notebooks, respectively. I would start there for now.
I would be happy to explore exchanging streams between the brokers, which I think we can start doing in an exploratory way, without (yet) formalizing format and registry.
What we do need to think about is how to keep the provenance link live. If everything relates to a single alert this is (relatively) straightforward, but what about information derived from some set of alerts, together with some catalog match and a fit algorithm? Ignore this, think of proper way to link this or consistently provide links to the information source?