While processCcd is happily running on most of the exposures, it remains a few problematic cases where it fails (at least on CFHT images).
From my experience I have seen the following cases:
Astrometry is not converging - This results in a FATAL error and the calexp is not produced for the problematic CCD. In these cases the standard astrometry may fail and aNet may succeed, it can be the opposite, or both can fail.
Astrometry is converging but the Astrometric scatter is crazy (very small or way too large). Same as before, standard may fail, aNet may fail, or both. In these cases, there is no warning printed out saying that the result is suspicious.
Astrometry is converging but the WCS computed from the tanSIP fitter is crazy. This one is particularly annoying as there is no error message printed out.
Photometric calibration fails because there is not enough sources selected as good stars. This is apparently related to a problem in the PSF determination.
Together with @nchotard and Philippe Gris, we will post plots to explain the problems and condition to reproduce them.
Whilst this in no way a solution to any of the actual problems here, it is just worth noting that you can still get a calexp out by setting the following config options.
# Raise an exception if photoCal fails? Ignored if doPhotoCal false.
config.calibrate.requirePhotoCal=True
# Raise an exception if astrometry fails? Ignored if doAstrometry false.
config.calibrate.requireAstrometry=True
Obviously this doesn’t solve the problems themselves, but it can be useful in debug to see if one might expect success by seeing what the calexp that failed looked like.
We are also seeing failures on HSC data (on visit/ccds that were successfully processed on the HSC stack). @rearmstr is currently looking into this on DM-6529.
Here is an example of the standard astrometry pretending to have converged with the following printout :
“processCcd.calibrate.astrometry: Matched and fit WCS in 2 iterations; found 10 matches with scatter = 0.000 ± 0.000 arcsec”
I guess that the scatter = 0.000± 0.000 simply means that the fit is under-constrained
Here is a ds9 image with USNO-A catalog overlayed :
We see that the stars at the bottom are completly off.
astrometry.net is also converging with 39 matches:
“processCcd.calibrate.astrometry: Astrometric scatter: 0.068277 arcsec (with non-linear terms, 39 matches, 4 rejected)”
The ds9 plot + USNO-A looks like the following :
@KSK The corresponding file is in : /lsst8/boutigny/improve_processCcd/rawdata/1094260p.fits.fz @nchotard will post some plots tomorrow showing the difference between aNet and the default astrometry.
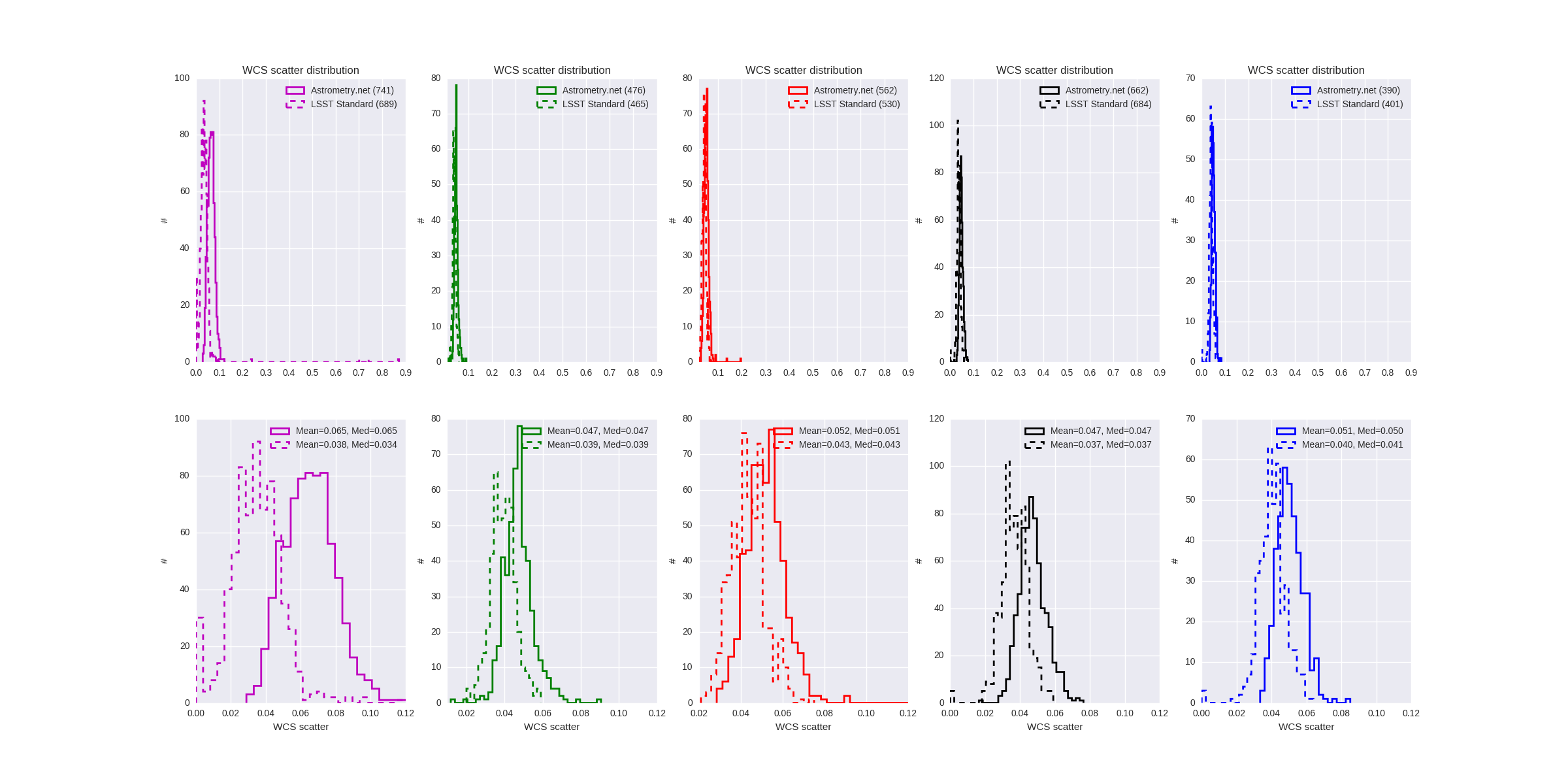
Here are two plots showing the astrometry scatter for aNet and the default astrometry. These are for five filters (ugriz) on about 100 CFHT images (~3000 CCDs). The first plot shows the astrometry scatter distributions for the two methods (bottom panels are zooms of the top panels), while the second plots shows the relation between these scatters for the same CCDs.
Over the five filters, the astrometry precision (given by the average scatter) seems better for the default astrometry, even though we get scatters of 0 with this method, as shown above by Dominique. There are a few outliers (scatter > 0.1 arcsec) when using aNet that we do not see with the default astrometry. Also note that one of these methods sometines failed for a given CCD while the other converged (and the other way around). I will try to put examples of such cases later today.
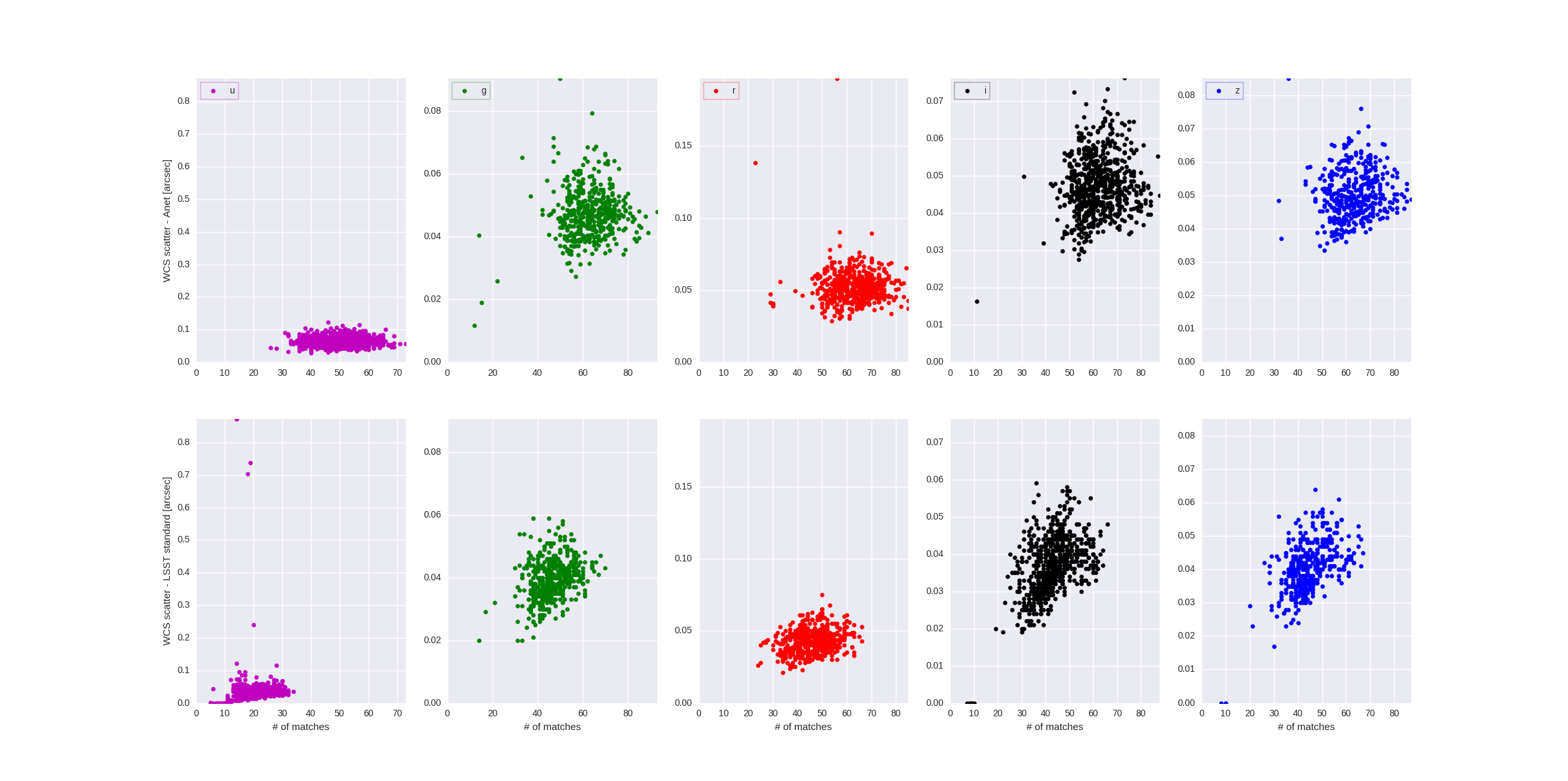
And as a raw explanation for the difference in average astrometry scatter (and 0 values for the default one), here is a plot showing the WSC scatter as a function of number of matches. A low scatter seems to be related related to a low number of matches. And Anet seems to be selecting more stars than the standard astromerty. For the latter, the scatter drops to zero when the number of matches drops below 10 (there is a case in u for which this does not apply).
The plots shown by @nchotard clearly demonstrate that the source selection implemented in the standard matcher is too tight. This is particularly obvious in the u band. But the root of the problem is not in the matcher but in the wcs fitter : https://github.com/lsst/meas_astrom/blob/master/src/sip/CreateWcsWithSip.cc which has 2 major problems:
The polynomial is fitted independently in x and y, so it requires a few iterations to converge
Even worse, there is no outlier rejection implemented in the fit
The fact that there is no outlier rejection in the fitter forces the matcher to be very strict on the source selection in order to avoid as much as possible outliers to enter into the fit.
I know that I have been saying this since years without much success, but I am absolutely convinced that we will not solve the recurrent problem that we have with the astrometry until we fix the fitter.
@boutigny and @nchotard Thank you very much for the plots. They are very informative. I see that there has been some progress on DM-3549. I know you have been waiting for these improvements for some time, and I’m very sorry it has taken so long to get around to them. This will definitely be a priority in the latter half of this cycle: Sept-Nov. if we don’t get to it before then.
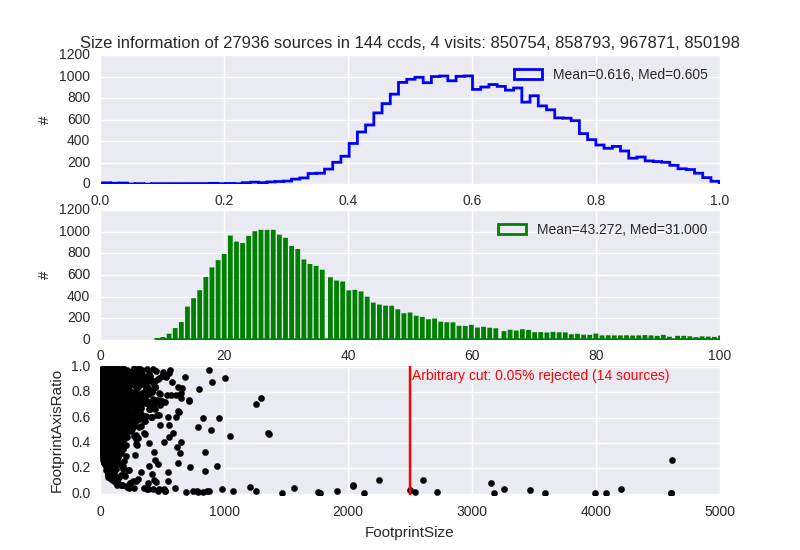
While running processCcd, I’ve encountered memory limit problems for a few visits having large sources (satellite trace or other artifacts). I’ve had to use a cut on the maxFootprintSize parameter of the deblender in processCcd (see below) to make sure that all my jobs at CC IN2P3 could run until the end of the script without hitting the memory limit (16GB in that case for the batch queue ‘huge’, which is the most we can get) when trying to deblend these sources. Without this cut, a few percent of my jobs (1 job per visit) were killed before processCcd had the time to finish running.
This cut if of course quite arbitrary and should not be the final solution to solve this kind of problem. I’ve found this jira ticket which seems to be related to this problem, along with this package.. Does anyone know if this package is included in the stack and already usable (or if we can test it)?
Here is the line I’ve added in the configuration file of processCcd, and a plot showing the distribution of the maxFootprintSize and FootPrintAxisRatio parameters of the deblender (taken for a few visits that were consuming too much memory) that I used to determine a reasonable value for this cut (and which allowed me to run the jobs). Sources above this limit were the ones causing the memory problem.
meas_artifact was developed on the HSC side, and to my knowledge we never fully integrated it into the stack there or ported it back to the HSC side. Before its developer (Steve Bickerton) left astronomy, he was reporting quite good results with it, and it’s been on our to-do list for a while, and just hasn’t risen to the top. If you’re willing to deal with what will likely be a number of small but easy-to-fix errors in porting it, you’re welcome to give meas_artifact at try now. I think this is the first case we’ve seen where artifacts caused significant memory problems on single frames (trhough we’ve seen the same need to apply the footprint-size cuts to avoid memory problems on coadds), so it hasn’t been a priority until now.
Yes, these seem like something we can instrument, as we’re doing with validate_drp, and have metrics regularly measured and reported on a web dashboard (e.g., SQUASH).
I’ve been working on an improved API/data model for validate_drp so that not only scalar metrics (like median scatter, for example) are reported, but also the full dataset are also available on the dashboard for rich distribution plots. I’ll have docs on this API soon, so this is just a heads-up that this is something SQuaRE can absolutely help with soon.
At the moment validate_drp is only being use to measure key performance metrics in LPM-17. But measuring known, real-world, pathologies is definitely something we should be doing.