Suppose you have a Jupyter Notebook that runs computations or gathers data, then presents an analysis of that data. Now suppose you want to run this notebook repeatedly: each time you process a new set of data or each time you modify an algorithm. And each time, you want to share those results quickly with colleagues.
In this post, I’d like to introduce you to a new platform that lets you do precisely that. We’re calling it the notebook-based report system, or nbreport for short.
Report repositories
Reports are Jupyter Notebooks. Typically you’ll develop and publish these reports on GitHub. Here’s an example report repository that @KSK helped create based on our Characterization Metric Reports:
https://github.com/lsst-sqre/nbreport/tree/master/tests/TESTR-001
A key feature of nbreport is that reports are templated using the usual Jinja syntax you’ve already seen in our Cookiecutter-based projects (like lsst/templates). You can template anything that needs to change each time you run the Jupyter Notebook.
You design notebook-based reports so that when these template variables are filled in, the notebook’s code can compute and generate the report’s outputs like tables and plots. Note that you can template both Python code and Markdown text.
For example, in the demo, @KSK is templating some identifiers for metric measurements stored in SQUASH, {{ cookiecutter.hsc_r_job_id }} and {{ cookiecutter.hsc_i_job_id }}:

When the report template is eventually rendered into a report instance, that cell looks like this:
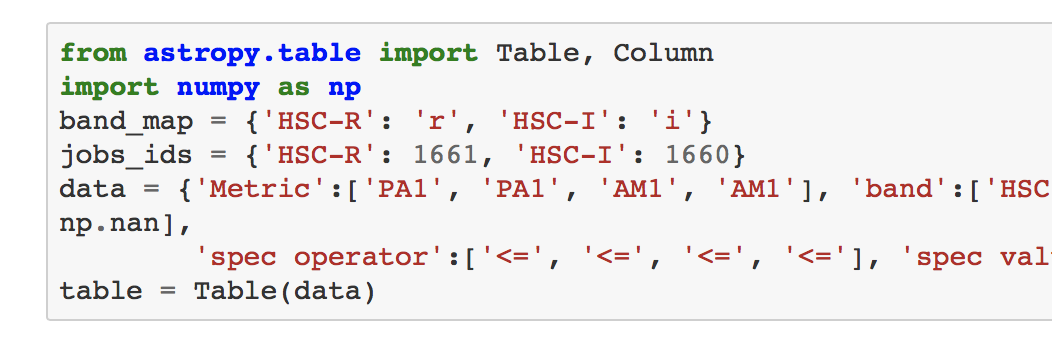
You might also template the URI of a Butler data repository and some data IDs in it. The possibilities are endless.
Creating report instances
Once you’ve crafted a report, you can start computing and publishing instances of it.
You’ll do this with the convenient nbreport command-line app (docs at https://nbreport.lsst.io). nbreport does these things for you:
- Clones a report from GitHub (or copies it locally).
- Fills in the notebook’s template variables with values you specify on the command line.
- Computes the notebook (you don’t have to open the notebook in the browser if you don’t want to).
- Uploads the notebook to our nbreport backend microservice that converts the report to HTML and publishes it to LSST the Docs.
Here’s an example of a published report instance (keep in mind this is an early preview and we’ll continue to improve the frontend):
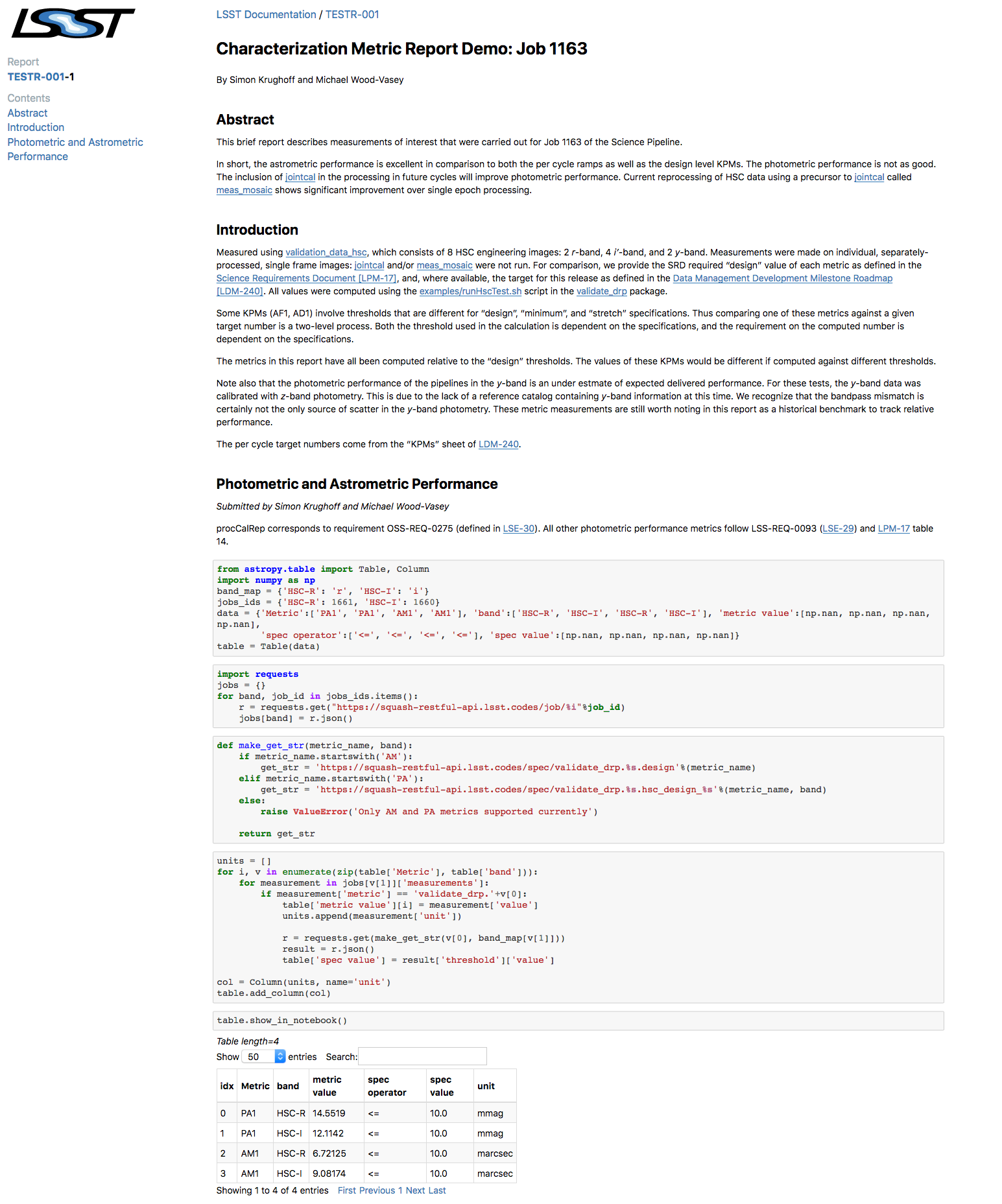
An element of the nbreport system we haven’t built yet is the homepage for each report. These homepages will not only list report instances but also let you filter and search for report instances based on facets like the date and template variables.
Designed for flexibility
Initially, we built nbreport to create nightly observing logs for LSST’s operations (SQR-026). In the short term, we think it will also be useful for pipeline developers and commissioning scientists. We’ve designed the nbreport client to be flexible to accommodate different workflows:
- Authorization is based on GitHub organization membership. As long as you’re a member of the lsst GitHub organization, you can publish a report instance. (Eventually, nbreport will be integrated with the LSST auth services hosted at NCSA.)
- You can create and publish report instances from any platform that provides the data and software your report needs, be it the LSST Science Platform, a continuous integration service like Jenkins or Travis, or even your laptop.
- For autonomous report generation, we offer an nbreport issue command that initializes, computes, and uploads a report in a single command.
- If you want to further customize each report instance, we support that too. You can use the nbreport init command to set up your report instance and fill in variables. Then you can work on the Jupyter notebook as you usually would, tweaking the text and analysis. Once the report is perfect, you can upload it with the nbreport upload command.
How is this different from technotes?
You might be wondering what makes notebook-based reports different from technotes.
Technotes are documents that you develop on GitHub and publish to the web through LSST the Docs.
Notebook-based reports also use a GitHub-based workflow, but only to develop the report’s templated notebook. Once a report template is set up, you can use it to repeatedly publish new instances of that report that communicates an analysis specific to the inputs you configure with template variables. Report instances are published straight to LSST the Docs and aren’t committed back to GitHub. In the vast majority of cases, you won’t make further edits to a report instance once it’s published.
At the same time, would Jupyter notebook-based technotes be a useful addition to our existing support for reStructuredText and LaTeX? Yes, we think so! Thanks to what we’ve learned building nbreport, I think you can expect to see Jupyter-based technotes in the future.
How to get involved
The nbreport system is still a preview. You can still get involved, though.
If you’ve got a project that might benefit from notebook-based reports, please let us know in this topic thread, or by talking to @frossie, @KSK, or myself at the LSST2018 workshop this week. We can work with you to start creating notebook-based reports.
Further reading
- nbreport documentation
- SQR-023: Design of the notebook-based report system provides technical background on the implementation.
- SQR-026: DMS end-of-night report the motivating use-case for nbreport.
- TESTR-001: Characterization Metric Report Demo is an example notebook repository on GitHub. An example report instance generated from it is TESTR-001-1: Characterization Metric Report Demo on LSST the Docs.
- lsst-sqre/nbreport is the GitHub repository for the command-line app.
- lsst-sqre/sqre-uservice-nbreport is the backend microservice for the nbreport system.