Hi, I have recently attempted to do a run through of the LSST Science pipeline tutorial only using Generation 3 commands line task and the pipetasks. I have managed to get up to the deblend task . I didn’t managed to get the measure task working therefore I also couldn’t do the mergeMeasurements task and forcedPhotCoadd task.
The main aim of me doing this run is so I can compare the overall time between processing the data
and storing it locally vs on a Object store (S3)
A quick comment from the Independence Day holiday… when you do queryDatasets the DatasetRef returned is fully-specified in that internally it knows the exact dataset that you want (the UUID for it inside registry). This means that any time you do a queryDatasets and then do a butler get with a dataset type name and a dataId you are forcing registry to do an entirely new query.
Butler.getDirect exists to allow you to bypass this additional query because you know exactly what dataset you want. What you want is something like:
Happy 4th of July even thought its the 5th July in the UK
On the latest version of makeDiscreteSkyMap.py on github on line 75 the getDirect is used incorrectly to my knowledge. You have probably have already spotted this already.
I know also in the version of my stack that getDirect(ref.getWcs) and getDirect(ref.getMetadata) also work.
Thanks for your work on this @joshuakitenge. I am also wondering how to create LSST-style reference catalogues using the stack. An updated (Gen3) version of these instructions would be very helpful:
Whether it’s more efficient to ask for the component or get the entire thing and then ask for the bit you want from it depends a lot on what datastore backend you are using. If you have local files it’s going to be much more efficient to just ask for the WCS and metadata from butler. If you are using S3 then the answer depends on whether you’ve used composite disassembly and store the WCS and metadata as distinct files in the object store. Otherwise it has to download the entire file first to get the component (and I haven’t added local disk caching yet so at the moment the file will be downloaded once for wcs and once for metadata). We added composite disassembly to make the S3 case efficient when asking for components.
But on balance it’s better to ask butler for each component separately if you don’t want all the pixel data because that’s more likely to be efficient or made more efficient in th future.
FWIW, I am currently working on updating the getting started tutorials at pipelines.lsst.io for gen3 butler use. This will included a whole new repository and instructions. I hope to be done with that this week and would welcome any feedback on the result.
One more comment, if you are experimenting with gen3 you really really don’t want to be using the formal releases. Gen3 is evolving really fast and even when v22 comes out it will have the gen3 software from the end of March.
You will be much happier if you are using the weekly releases for your gen3 testing (we are using w25 on the IDF at Google for example but we expect to bump that as required).
Gen3-native refcats is something that we do have to sort out fairly soon (DM-29543). Relying on 2to3 for them is untenable given that we are planning to start removing gen2 in early 2022.
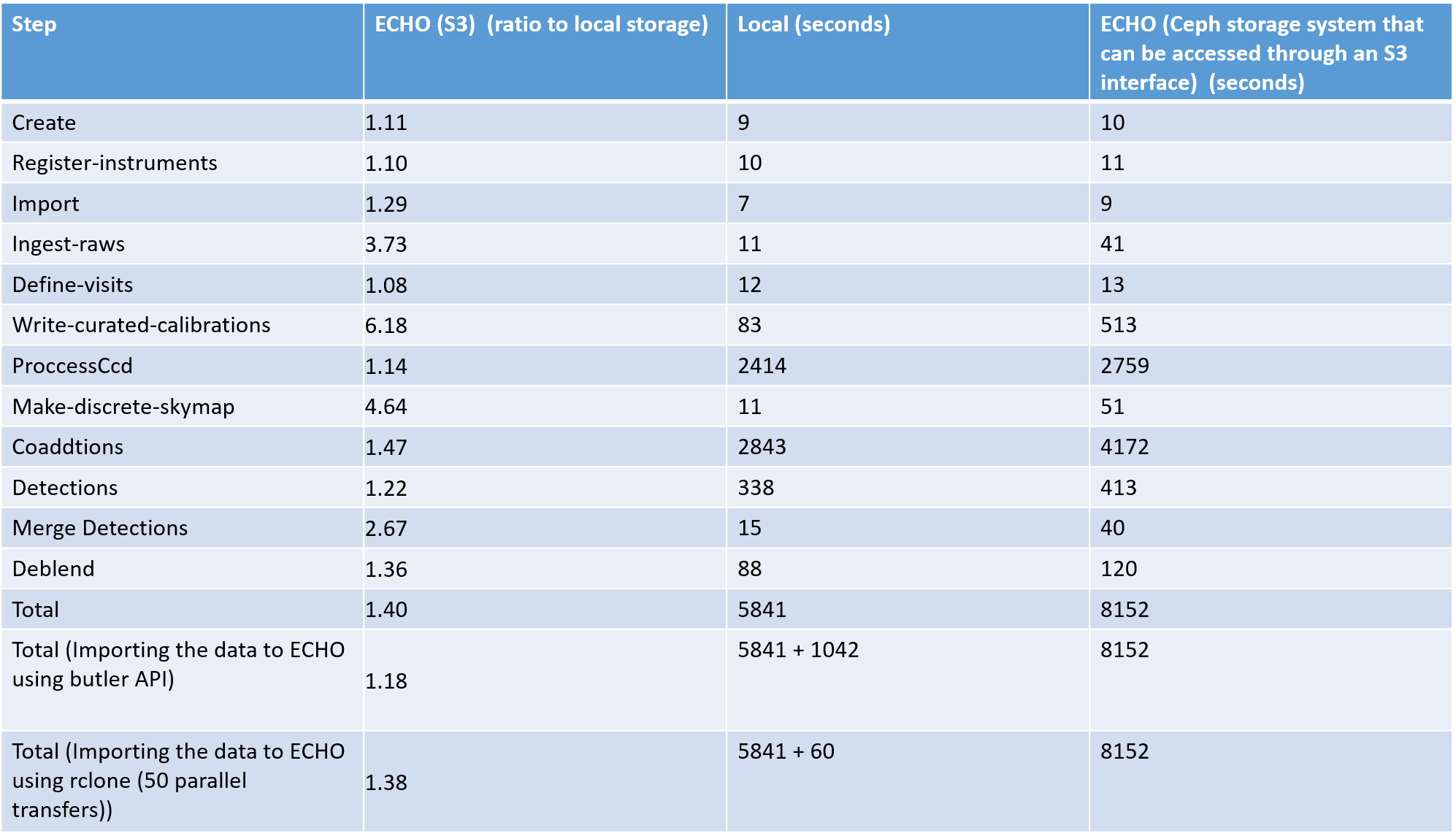
Hi , I have started to do some initial basic tests of the overall time taken to run each of the command. The table below shows how long each command took to run where the endpoints was local storage and object store respectively.
I have also created plots on the IO statistics (IOwait , reads and writes) , CPU and RAM usage. If anyone would want to see these just drop me a message or an email (joshua.kitenge@stfc.ac.uk).
(processes = 1 on the pipetasks)
Thanks for looking at this. It’s really great. Some comments:
What does create mean for ECHO? Are you using local sqlite file but ECHO datastore?
What is being imported in the Import step?
For ingest-raws are you ingesting from local disk to ECHO or ingesting from the raw files in the ECHO bucket? If ingesting from local then there will be the transfer overhead (and I haven’t parallelized the S3 copies). If ingesting from the bucket each file has to be downloaded so the header can be read from it to extract the registry information. This can be sped up considerably by writing index files for the raw files (astrometadata write-index) and putting those in the bucket as well. The ingest-raws command will then download the small JSON files rather than the huge fits files.
define-visits is entirely registry based so I would not expect any difference between the two.
write-curated-calibrations reads lots of ECSV/YAML files into memory and then writes out transformed FITS files. This will write each file locally and then transfer it to the bucket so I assume that’s where the slow down is coming from. It does not attempt to batch up those transfers (datastore.put can’t be given multiple DatasetRef for now).
make-discrete-skymap is going to be slower because currently we do not cache the file locally when using S3. This means that the get of calexp.wcs downloads the full file, reads the WCS, then deletes the local file, and then calexp.bbox does the same thing. You could enable caching for calexp by changing the configuration file for datastore but I haven’t enabled it because I don’t have cache expiry. One thing I would be very interested in is how your timing changes with ECHO if you use composite disassembly – in that datastore mode I wrote components out as separate files such that calexp.wcs only downloads the WCS part. You can see how to do this by looking at pipelines_check.
Yes, the registry is stored locally for ECHO . I used --seed-config “path to sql file” --override
The reference catalog from the converted gen 2 LSST science pipeline tutorial.
In this case the raws files are stored locally and ingested into ECHO. I’ll try the other method you have suggested and I’ll assess the timing difference.
I’ll look into using composite disassembly and try to get some analysis done by the end of next week.
Recreating the LSST Science pipeline tutorial (gen 2) only using Generation 3 command line tasks and the pipetasks using release w_2021_30. I still didn’t managed to get the measure task working therefore I also couldn’t do the mergeMeasurements task and forcedPhotCoadd task(different error to what I got last time)
Note that v22 is not at all related to w_2021_30, and using packages from these two in combination is likely to fail. As it says at Release 22.0.0 (2021-07-09) — LSST Science Pipelines, the release is based on w_2021_14 plus a patch.
Hey @joshuakitenge, I work on all the gen3 processing user facing bits and would be happy to help you out on this, it might take me a few minutes to get up to speed though.
If I understand correctly, you are trying to follow Getting started with the LSST Science Pipelines — LSST Science Pipelines in context of gen3? If that is the case I can understand why you are having trouble, all of that is not really applicable. To make things more confusing, many of the tasks contain code to make them run in gen2 and gen3, so its possible to end up somehow mixing and matching in a confusing way (for instance command line tasks simply do not exist in a gen3 framework).
I’m going to try to pull together some information for you, but I wanted to drop a note to let you know I am working on it. While I do that, what are you interested in specifically, processing data? ingesting data? running analysis against processed data?
Hey, @natelust, I have recently started at STFC, RAL as a Scientific Computing Graduate in the Tier-1 group where I’m going to be curating and serving astronomy survey images on the Echo (S3) Object Store (ECHO is a Ceph storage system that can be accessed through an S3 interface ).
I’m interested in all 3 of these.
Processing data
I’m interested in the overall time between processing the data and storing it locally (Openstack vm ) vs on a ECHO (S3) Object store. To assess if using ECHO (S3) Object store is a viable option compared to local. This is to help alleviate disk pressure (e.g. on a HPC) for Scientist that are processing the data in the future (GEN3).
I’m also interested in studying and documenting as much information about Generation 3. To help LSST:UK and hopefully the whole of LSST community understand LSST science pipelines better.
Ingesting data
One of the aims of my work to serve processed and raw LSST data on ECHO (S3) object store.
I’m planning on testing ingesting the raw files using astrometadata write-index. To optimize the workflow
Running analysis against processed data
Currently I’m testing authentication/authorisation workflows that allow federated end user (Astronomers) access the data that would be stored in ECHO through a jupyter notebook.
The jupyter notebook workflow works using master S3 credentials into ECHO, however this is not the workflow we want to give to our end users. Currently we are looking workflows where we authenticate user using an IAM service and through IAM service the end user are granted temporary S3 credentials(read access) so they can access the butler repo stored on ECHO to do their analyse.
We are committed to supporting object stores for processing and welcome any feedback you give us. I will have to sort out file caching at some point because we are planning on adding quantum clustering to the workflow graph so that a single job can run multiple quanta – this will make use of caching by noting that the next quantum will be able to read the output locally from the previous quantum without having to fetch it from the object store.
I am also wondering whether we should add asyncio support to ButlerURI and allow a bulk butler.put that can parallelize the file transfers on job completion. Allowing a bulk ingest that can use ButlerURI.transfer_from() with asyncio might be useful as well.
There are two formats of index files so you get to choose. One stores the translated metadata and the other stores all the FITS headers. Translated metadata is he smallest and fastest to process but we probably will use the raw header option in the index because that form allows us to modify the header translation and reingest without rewriting the index file (so the index file can become a permanent read-only artifact).
We haven’t used these index files “in real life” and there has been talk of allowing an option that writes the index files to a parallel directory tree rather than storing them directly alongside the raw data. Doing that makes it easier to delete and rebuild them without having to touch the curated raw folders.
A lot of this also assumes that these index files are created incrementally as new data arrives (and so the headers can be read during data transfer) but of course creating these index files from pre-existing data in buckets still requires download of the entire file. I have been considering the ability to read the first N-bytes from the file to minimize the download. This should work fine for LSSTCam data but for DECam it won’t work because DECam files store multiple detectors in a single file.
Our plan for the IDF is to have a butler client/server that uses the science platform A&A system to access it and returns signed URLs that clients can use for reading from and writing to the object store. Science users will not have direct access to the registry SQL database.

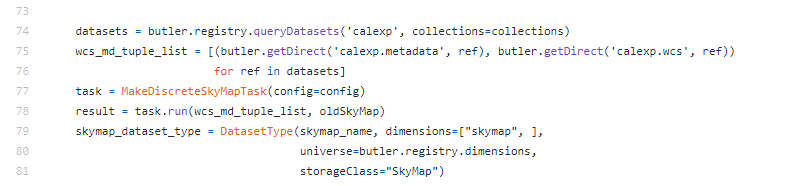
 , cheers for the correction
, cheers for the correction