okay, good. I enjoy jupyter better, even though I’ve been doing unix work for a long time.
thanks, I’ll keep chiseling away…
thanks again Joshua, all your posts are very helpful.
I’ve worked my way through pass #3 attempt at running the GEN3 pipeline. I’ve reached the ProcessCcd step and had to pause. The ONLY step I’m still not happy with is the “hack” to get a reference catalog properly added to the new repository.
So, if your next version, can you articulate the steps you took to get your ref catalog established.
I can see all the steps, but it seems like a lot of effort just to get the refcat set up. I don’t believe I’m the only person with the same questions.
I’m continuing with getting an export/import done, but still not happy with this “hack”.
Fred klich
On a common sense note, is it possible that someone has a .sqlite3 file that is the PanStarr refcat that can be easily added to the GEN3 repository [since it should be same for most of us newbie tutorial workers] that can be shared for the community. At least we can get by this hack step and get back into the heart of the GEN3 pipeline.
Fred , Dallas, Tx
No-one is happy with the hack. We are actively working on fixing this as has been mentioned multiple times in the discussion above.
butler does not use sqlite databases for the refcat file format. We shard the catalog spatially so that the required subset for a particular visit is efficiently accessible.
I understand. I believe I know my steps through the ref catalog part…I’ll restart and probably break into daylight here…but still learning a lot.
I started GEN3 regarding it as a pipeline “tutorial”, per it’s title. I now understand it is a prototype WIP. And, to be truthful, I kinda like it that way better.
Thanks for your help Tim.
Tim, do I need any special status to be able to fully navigate Jira?
It’s more than a prototype. The refcat bit is the only part that is problematic since it needs a gen2 repo to bootstrap it. It’s all evolving rapidly but it does work.
All DM tickets are public read-only. You need to be a project member to be able to modify tickets. There is a public RSS feed and you should be able to bookmark a query if there are specific types of tickets you want to see progress on.
Hi, Here is my latest GEN 3 tutorial run, where I have used the correct method to remove the “BRIGHT_OBJECT” that @natelust suggested in an earlier post. Instead of the hack in the prior tutorial
Gen3 run-w_2021_34.html (1.2 MB)
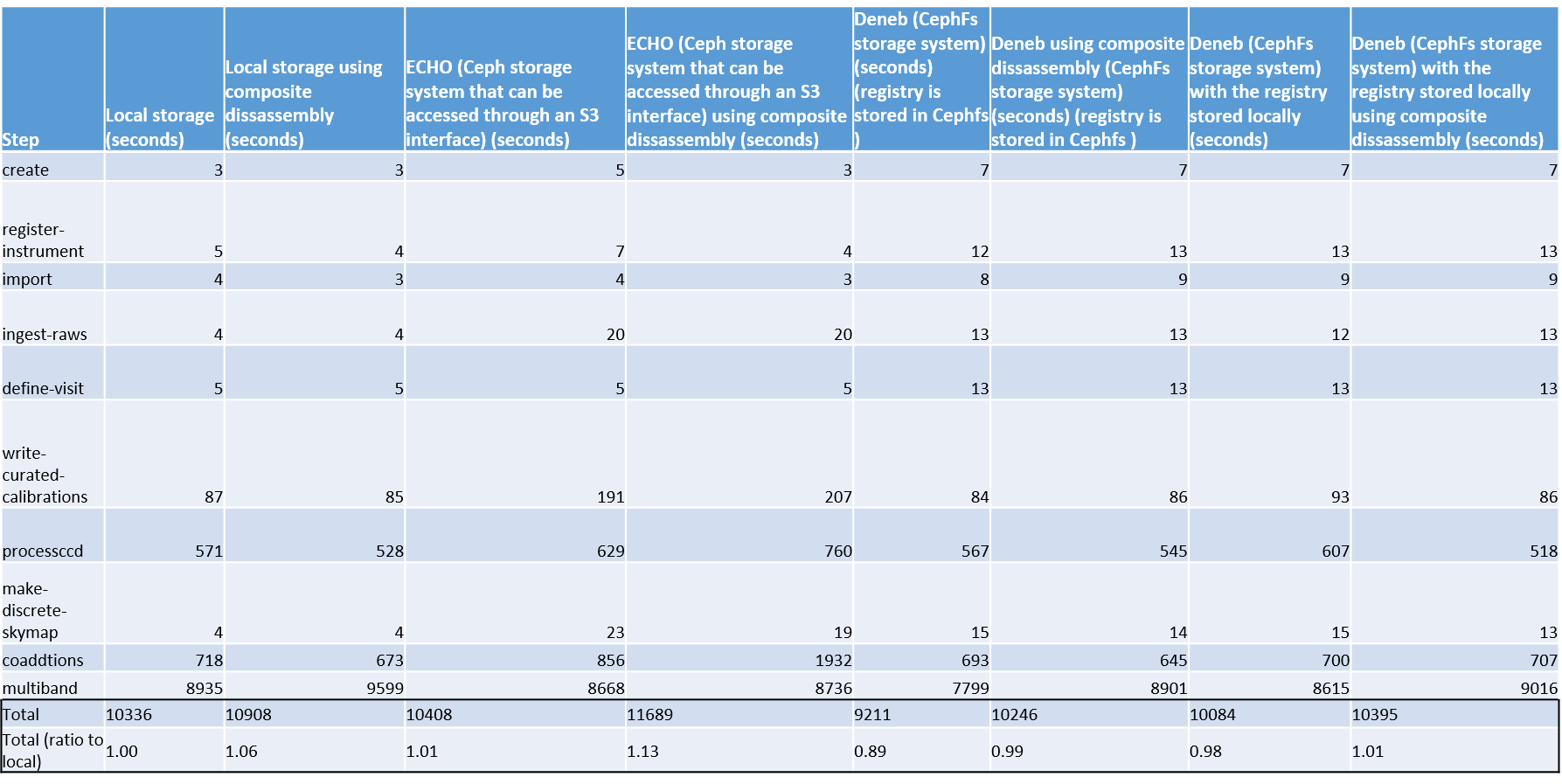
- I have redone the timing test using the latest version of my GEN 3 tutorial. This latest version uses 8 processes for the processccd, coaddtions and multiband stage.
-
I also did CPU, MEM and IO (disk and network) profiling on each of these steps, if you want to see how I did the profiling click here (GitHub - joshuadkitenge/LSST-RAL-ECHO-EXP ).
-
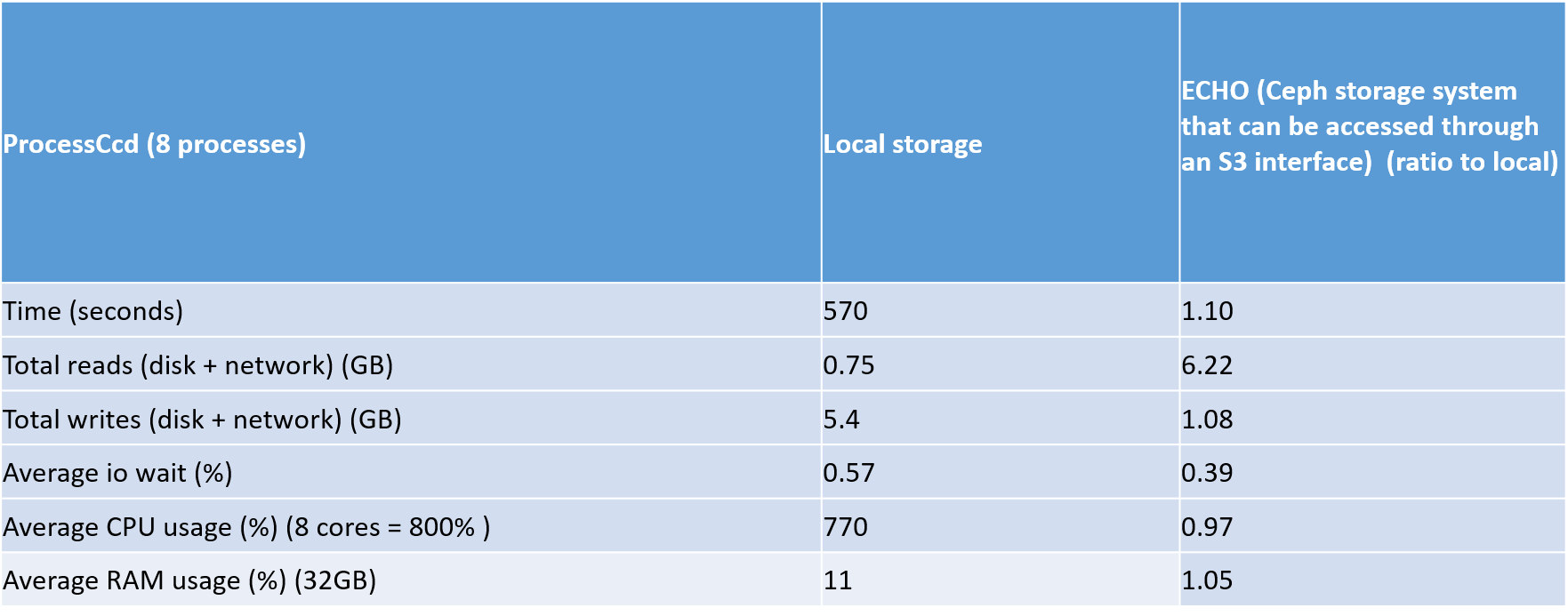
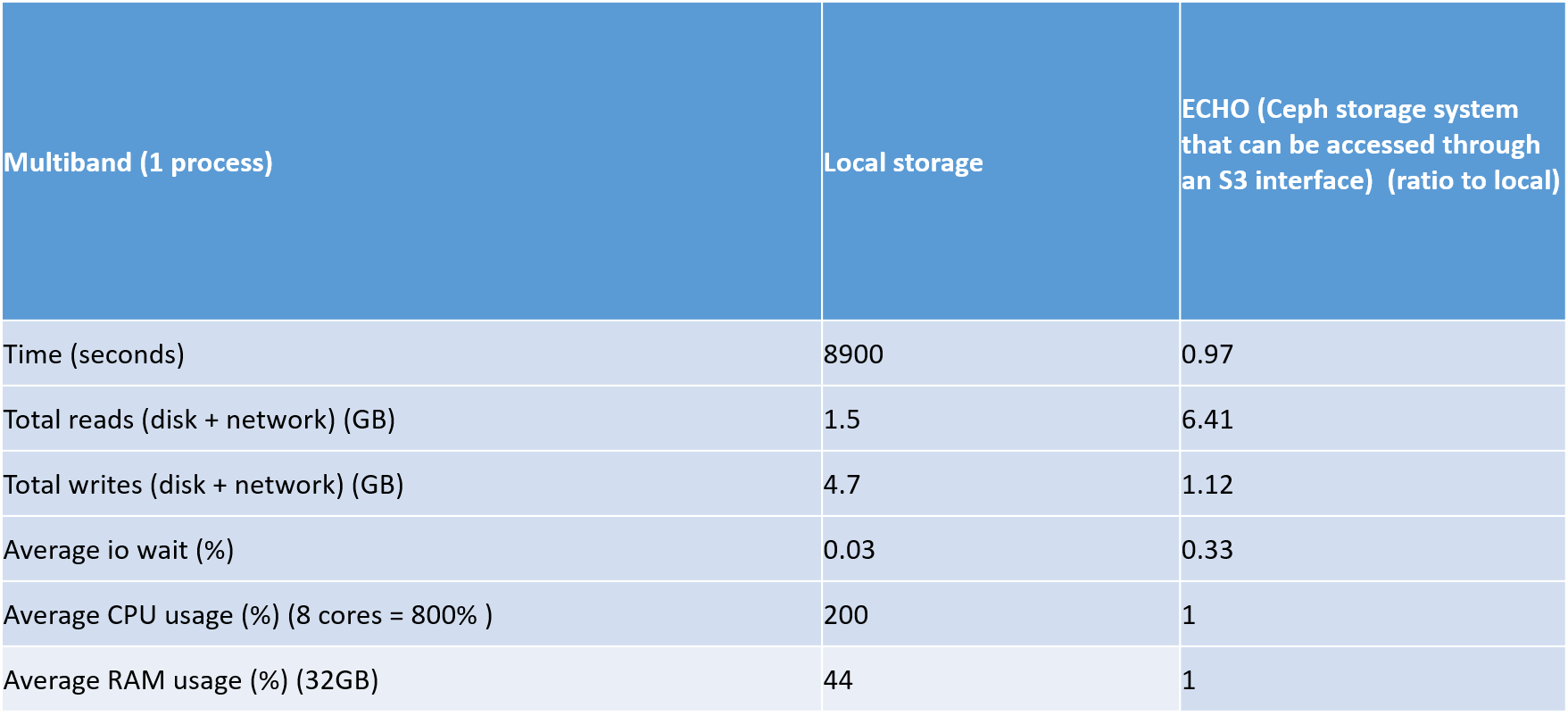
The most interesting aspect of this test is how local storage will compared to ECHO storage for the multiband , processccd and coaddtions steps. Look below for the relevant tables

-
The most interesting results of this test was the ratio of the total reads for local storage compared to ECHO. This ratio was really high, especially in the coaddtions step.
-
Another interesting aspect of this test is that the mulitband step seems to be bottlenecked as the mean CPU usage is 200% (800%= 8 processes) and also the average memory usage in this step is fairly high at 14 GB.
-
The overall timing differences between ECHO and local is only 1% but I think that is because most of the processing time is done in the multiband step
-
The main question I have about all the results that I have got from my testing, is that would you have expected these results ? Or is there some weirdness happening
Can you say the commands you are running for this test?
I have realized that composite disassembly uses much more disk space because the code path writing the FITS files does not have FITS file compression enabled. I will try to take a look at that in the near future.
Depending on whether local temp directories are included in these numbers you might see at least twice the writes because for object stores we generally write the file to local disk first and then push that file to the object store (which means one extra write and one extra read on the client). The object store will only see the one write though. When we get from the object store we will write the file locally and then read it. None of this really explains even the first set of numbers for process CCD where you get 6x read but only 1x write. In fact your writes are almost the same as before but your reads are 6x, 49x, 6x…
I have just finished the object store caching code (it’s here but is being reviewed) but I don’t know enough about the coaddition step to be sure if this would help at all. 49x seems too large. @natelust is coaddition doing anything interesting with repeated access to data (especially components)?
1 Like
The butler commands and pipetask I’m using are similar to the ones used in this script (just with different endpoint storages and configs )LSST-RAL-ECHO-EXP/GEN3_run.sh at master · joshuadkitenge/LSST-RAL-ECHO-EXP · GitHub
The profiling commands I used was:
- ps for CPU and RAM
- iostat for the disk profiling
- IFDATA for the network profiling
Without caching (under review!), @timj tells me that each butler.get() is going to pull the entire file down even when reading a sub-region. And in coaddition we stack in sub-regions to keep the memory from blowing up. This is most likely the source of the 49x (and I’m surprised it’s not larger; it depends on the subset being used). After the caching ticket has been merged, it would be great to run your test to confirm that the file reads go down.
1 Like
Multiband is where all the deblending and measurements take place. Those together take a lot of ram/cpu, much more than other stages. Deblending needs to load in all bands at once, and create many intermediate arrays in order to separate blends into individual objects and inflates the number of sources detected by several times, which then means many more sources to run measurement on. Because multiband is run after coaddition, many more faint objects can be seen, increasing blends significantly.
1 Like
Hey Tim, hope you’re faring well. Still hotter n you-know-what here in Texas.
Anyway, I did manage to work my way through Gen3. Now prepping to repeat it, hopefully more gracefully this time.
Here is my question. I’m restarting with w_2021_34. I want to clarify that as I follow the Gen3 run-w_2021_34.html summary, I really am not dependent upon the gen2 (v22) repository that I built during my gen2 exercises…that is, other than the steps to steal the refcat information for Gen3.
To put it another way; Gen3 is standalone tutorial , entirely separate from the Gen2 version.
Hopefully this ?? is clear.
thanks,
Fred klich
Tucson is hot.
I’m not sure which tutorial you are talking about. The new gen3 tutorial is almost ready to be released. Gen3 is completely standalone except for the refcat problem which should hopefully be fixed in September.
…not sure which tutorial…
The steps shown in Gen3 run-w_2021_34.html
Thanks Tim. Stay cool.
Okay. Please remember that Rubin didn’t write that tutorial.
okay, kinda good to know. I have very little appreciation of all the roles/identities/groups/etc… I expect the official Gen 3 tutorial will be coming in the future.
Tim, is it out of line to have phone dialog with you during your on-duty hours?
Fred klich
Tim
“Rubin didn’t write that tutorial…”.
Can you advise if there is another more official draft tutorial?
Fred klich
I have fixed this. In the next weekly (tomorrow) the disassembled composites take up roughly the same space as the big FITS file.
Any/all pipeline experts.
So far, I’ve had no issue running the Gen3 tutorial, following Gen3 run-w_2021_34.html .
In executing this step:
butler make-discrete-skymap GEN3_run HSC
I receive:
Error: Missing option ‘–collections’.
I try:
butler make-discrete-skymap ./GEN3_run HSC --collections HSC/calib
…even though I was not sure which collection to reference…
and I receive:
RuntimeError: No data found from which to compute convex hull
I use the query-collections option and I get:
Name Type
refcats/gen2 RUN
HSC/raw/all RUN
HSC/calib CALIBRATION
HSC/calib/unbounded RUN
HSC/calib/curated/19700101T000000Z RUN
HSC/calib/curated/20130131T000000Z RUN
HSC/calib/curated/20140403T000000Z RUN
HSC/calib/curated/20140601T000000Z RUN
HSC/calib/curated/20151106T000000Z RUN
HSC/calib/curated/20160401T000000Z RUN
HSC/calib/curated/20161122T000000Z RUN
HSC/calib/curated/20161223T000000Z RUN
processCcdOutputs RUN
So, can anyone suggest what specific collection I am supposed to use. I thought it was to be one of the calibration collections.
Many thanks,
Fred Dallas, TX