Hi everyone,
I was recently at the Boutique Surveys and Experiments workshop that Shri Kulkarni organized at CalTech. Here’s a quick writeup with some early general impressions while they’re still fresh (more details may follow).
I was approaching the workshop from two points of view. First, to learn what’s interesting scientifically – that worked wonderfully, but is highly subjective so I’ll skip that part for now (plus, I just saw a very nice writeup by Steve Ridgeway which we could ask him to post here).
But I was also there to understand where software in boutique surveys is going over the next 5-10 years (and what large projects can do to help and/or benefit). Some musings on the latter:
-
There’s an explosion (pun intended) of synoptic surveys for time-domain astronomy. Technological improvements and “COTS-ification” of really good hardware have done wonders — cheap CCDs, lenses, networking, disks space, computing, etc. But I worry that improvements in data reduction pipelines are not keeping pace.
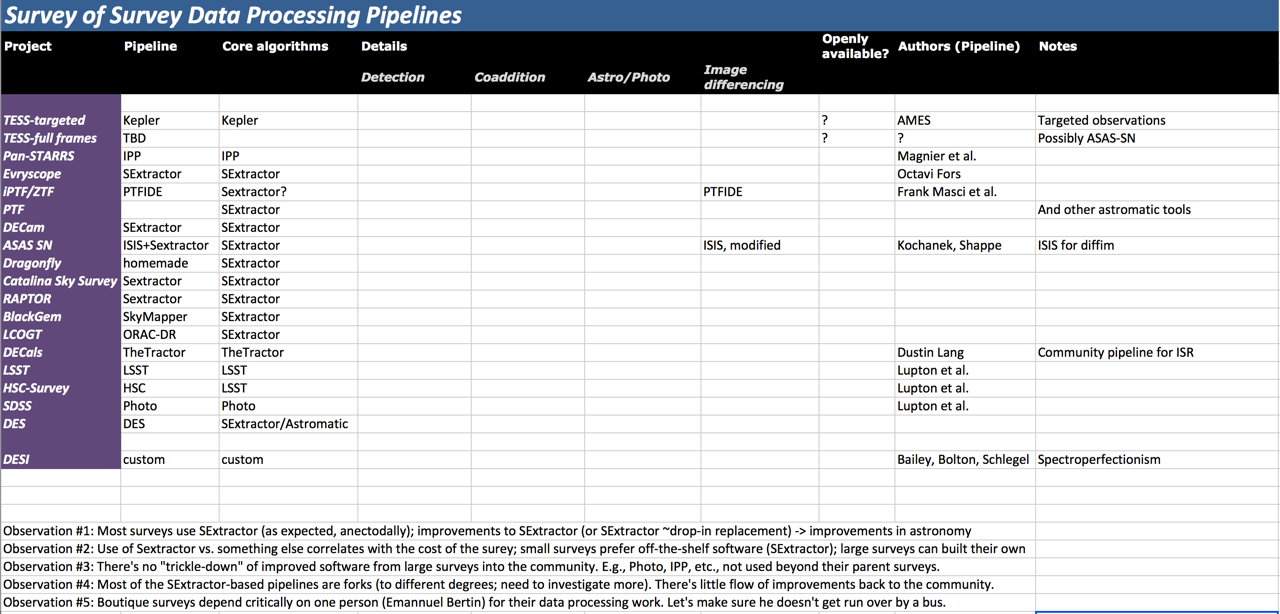
Though the talks, I decided to keep track of who’s doing what wrt. data processing. I started distilling it into a spreadsheet (screenshot attached; still very rough). I’ll expand into something more accurate/complete over the next few days and put somewhere on a website with a lot more detail. A few observations about this:
-
Most (~60% or so!) surveys mentioned use SExtractor in one way or another (see the attached screenshot). Anecdotally, this is what I expected, but it was still striking to see it in the data. SExtractor (and the AstroMatic suite) are the “COTS” (ok, “OTS”) science pipelines of astronomy. The corollary is that improvements to SExtractor (or SExtractor ~drop-in replacement) would probably “lift all boats” across the board when it comes to small projects (but see obsv #4, below). On the less bright side, it’s risky for the community to depend on one package that much (that is very close to “bus factor” of 1).
-
The use of SExtractor vs. something else correlates with the cost of the survey. Small surveys prefer off-the-shelf, familiar, stuff; they can’t afford to spend much on data management (or at least perceive that to be the right tradeoff vs. hardware). This is, again, unsurprising, though I think skimping on data reduction may become more costly than doing it right ([citation needed]).
-
Still, a lot of money is going into software+algorithm development for large surveys/telescopes. But, worryingly, there’s no “trickle-down” of improved software back into the “boutique” community (and “boutique” these days is surveying full visible sky, down to 16th mag, w. 2-minute exposures, continuously). E.g., Photo, IPP, PTFIDE, etc., have seen little use beyond their parent surveys, though in some ways they’re much stronger than SExtractor. Image differencing (and coaddition) is in a generally pretty sorry state out there. And techniques like ubercal are not being talked about.
My hypothesis is that this is because the larger projects tend to (by default) be relatively myopic about the broader impact their data reduction software can have. On one hand, the funding agencies (justifiably) worry about scope creep, so generalization for “community use” is difficult to justify. On the other, in chasing 10x better results, we sometimes lose sight of what we already have — for the majority of people out there, even 20% would already be phenomenal.
I think that that’s why the possibilities of the newly written “big project” codes (or developed algorithms) are not well advertised (esp. among survey builders). And, for similar reasons, we also don’t think about making simple things easy and documented (thus turning off adoption).
I think we all agree that’s not great — it’s perverse to be spending >=$100 million or so on software (between LSST, PanSTARRS, WFIRST, ZTF, and all other “big” surveys; just my guesstimate), w/o the benefits of that work finding their way back to everyone trying to build more specialized projects. The technical obstacles are not that huge. I think this is mostly about adopting the attitude that big project code should be written to help the community (as well as benefit from community contributions — see my next point). In particular, we (the LSST) can make a huge difference with the pipelines and algorithms we’re building (and will benefit from the feedback).
-
Observation #4: While most projects use SExtractor in one way or another, chatting to people I got the impression that most SExtractor-based pipelines are forks — heavily modified and customized. Two problems with that:
-
Some of those customizations are to work around specific problems within that specific survey, but some (most?) are fixes that should’ve been flowed back to the “parent” code that Bertin maintains. Anecdotally, it looks like that isn’t happening. So each project seems to be rediscovering same/similar problems, and re-implementing the similar/same fixes.
-
Secondly, because of the heavy customization, many project can’t just take Bertin’s “latest and greatest” and drop it into their pipelines. Some people are running SExtractor that’s a decade old. All of that leads to poorer photometry, lower reliability of the pipelines, etc… And less (or not as good) science, in the end.
-
-
- Bottom line: Lot’s of unnecessary duplication, lots of room to do better, and lots of room for us to help.
-
I was struck by just how much data will be collected by these projects over the next few years! These surveys may be boutique, but when you’re imaging (close to) the entire sky, you’re imaging (close to) everything whether you want it or not. And that is valuable! I think I’ll need to start another spreadsheet to track that.
For example, just between Evryscope, ASAS SN, various DECam programs, CSS, and iPTF, the entire sky will be covered, many hundreds of times. Yet most of these data (especially, catalogs) will remain inaccessible (and likely sub-optimally processed or not fully processed at all — see previous point), mined only to the degree needed to make the (boutique) experiment successful. It’s understandable and the right short-term thing to do from the perspective of a PI — small projects have no money and time to deal with this. But it’s a strange overall choice (for us, as a community); the marginal cost in making these data available would be (relatively) small, and the impact would be even greater if they were processed with state-of-the-art codes (see point I.). Again, “boutique" is now all sky, all the time, to ~18th-ish magnitude depths.
-
From the point of view of LSST, these surveys may be useful in informing the cadence discussions. These are just now starting in earnest, and everything is on the table to maximize the total science output of the telescope. Hearing what worked and what didn’t will be useful.
-
It’s too bad that these talks weren’t recorded for later (re)viewing — they’d make for an excellent introduction into what’s currently being done in time domain astronomy. Also, no agreed-upon hashtag (though I didn’t have time to tweet anyway).
-
Finally, I was reminded how infrequently the data processing gurus of the world (those with and w/o shoes) meet to discuss current problems in image processing and exchange experiences. @rhl, we should revive those ideas about putting together the software counterpart to PACCD. Or, as @jbosch proposed in a mailing list conversation, an Aspen workshop.
Hope you find this useful,
– M.