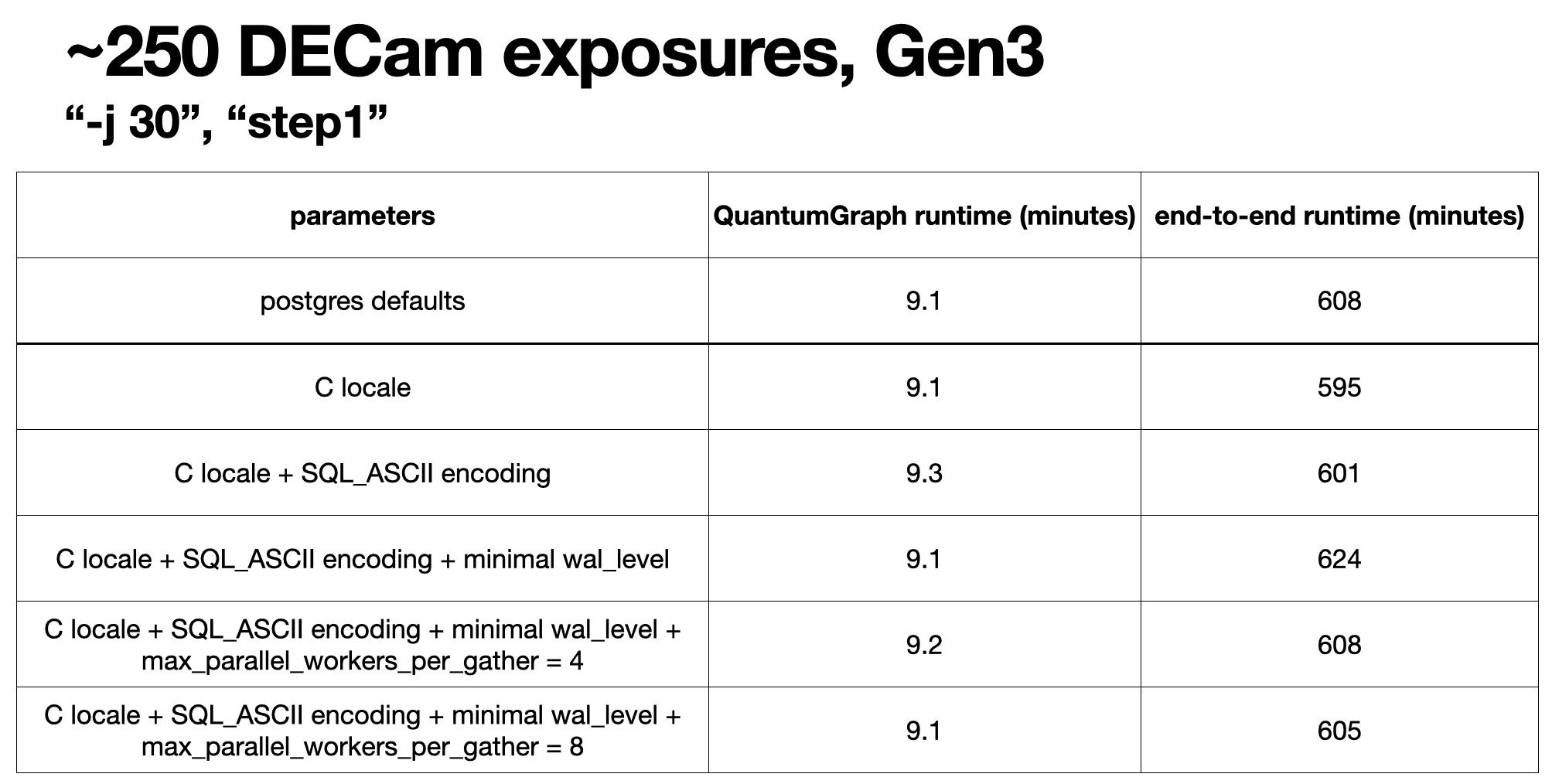
Our NOIRLab group has been working on processing large amounts of DECam data with the Gen3 LSST pipelines. We have found that using a postgres database back end for Butler has led to major speedups compared to the default of SQLite. So I had also been wondering whether further performance gains could be achieved through tuning of various postgres configuration parameters. Thus far we have not been able to identify any postgres configuration parameter changes that make a major difference. The following table shows the postgres settings we’ve experimented with in the left column (LOCALE, LC_COLLATE, LC_TYPE, ENCODING, WAL_LEVEL, MAX_PARALLEL_WORKERS_PER_GATHER). The other columns show basically no appreciable differences in run time when varying these postgres settings.
I’m hoping that folks in LSST DM and/or community members who deploy large LSST pipeline processings (e.g., Merian/HSC) might have some advice about postgres optimization for best performance? For instance, which specific postgres configuration parameters we should be looking at. If anybody is willing to share their postgresql.conf file and/or results of sysctl -a (for server kernel settings) those would be of particular interest. We’re using psql version 15.1. Thanks very much.
When you use pipetask run it does interact with the database at the start and end of every quantum. Do you see lots of connection contention during your -j 30 testing? It should generally be a small fraction of the time spent running the algorithms but once you have thousands of quanta executing at once you will bring the database to its knees.
For production we deliberately do not interact with the database once the quantum graph is created. BPS creates the graph as normal but sets up the runtime environment such that each job being run by the workflow system runs independently of the database. We have one job that runs at the end that transfers the data products back into the registry.
I don’t know anything about how we configured our Postgres database at USDF (we use pgbouncer in front of it).
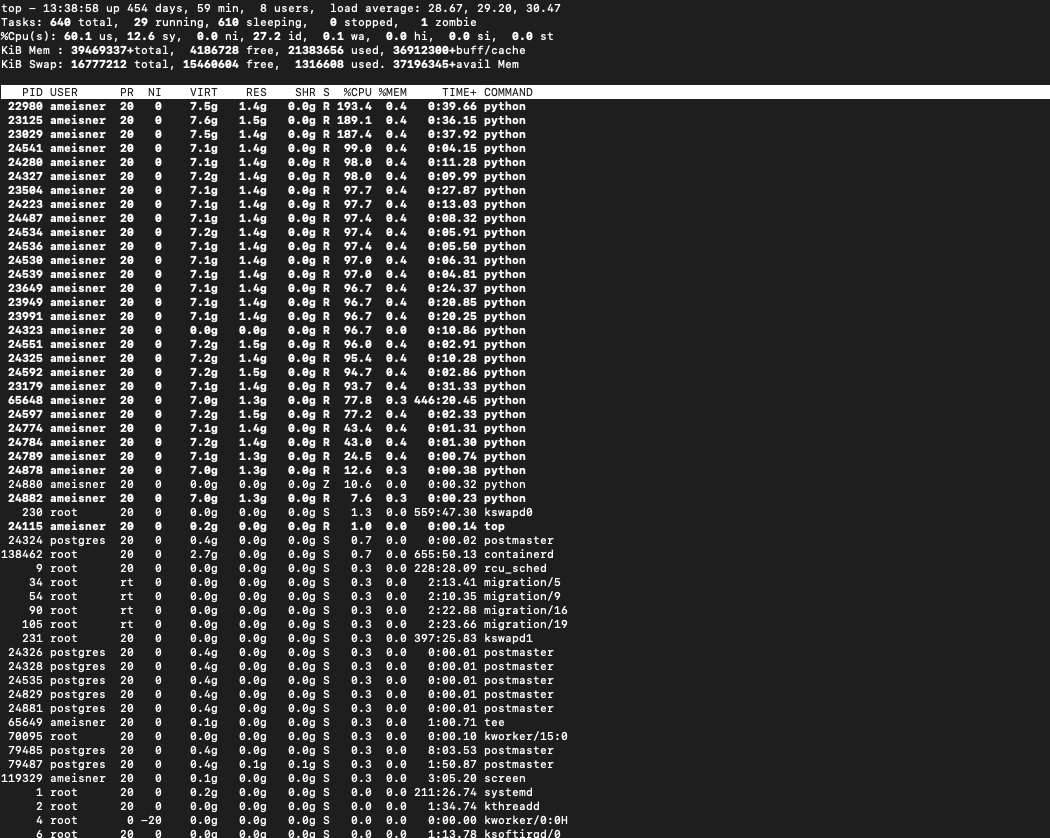
We have indeed been using pipetask run. When using postgres for the Butler database we don’t think that we see much connection contention. With -j 30 it seems like most (but not quite all) of the 30 requested Python processes are using close to 100% CPU at any given time. I’ve attached an example top screenshot illustrating this.
Does this mean that for production DM uses something other than pipetask run?
I had not heard of pgbouncer before but we can look into it. Thanks!
That’s fine. When you try to run 10,000 quanta simultaneously your database will fall over if they are all using the default pipetask configuration.
We use BPS to submit jobs to a workflow system (there is a summary of that in the SPIE paper). We can currently use parsl+slurm, htcondor, or the LHC PanDA system but it’s a plugin system so supporting pegasus or something else should not be a problem.
The trick is that BPS sets up the execution such that each job is isolated and is not talking to the original butler registry at all (it’s still writing to the datastore). Once the workflow completes a “merge job” runs to register all the output datasets with the original butler registry.
Currently BPS creates a sqlite database that is copied to each job. That’s a bit wasteful so we are currently testing a scheme where we will use the quantum graph itself as a read-only registry. pipetask --help with a recent weekly will show you the new commands that allow this to work (along with butler transfer-from-graph). This will all be hidden from the user so they won’t notice when BPS switches from sqlite to graph execution, other than things being a bit more efficient.
Thanks, K-T! We noticed that the alpastor/cnpg-butler-database.yaml file has a much higher shared_buffers value (16 GB) than what we’ve been using (128 MB), so we will try increasing shared_buffers to 16 GB. We are also going to test setting the vm.swappiness kernel parameter to 0.