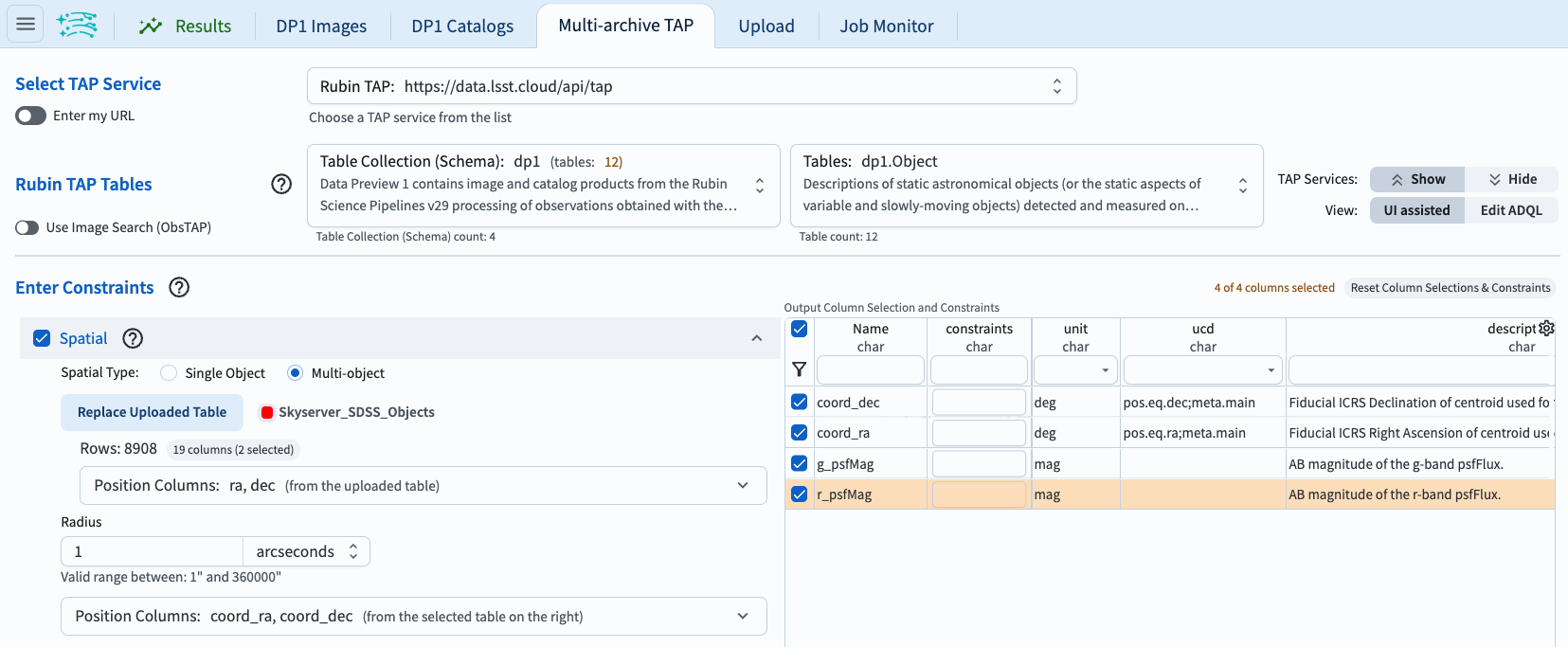
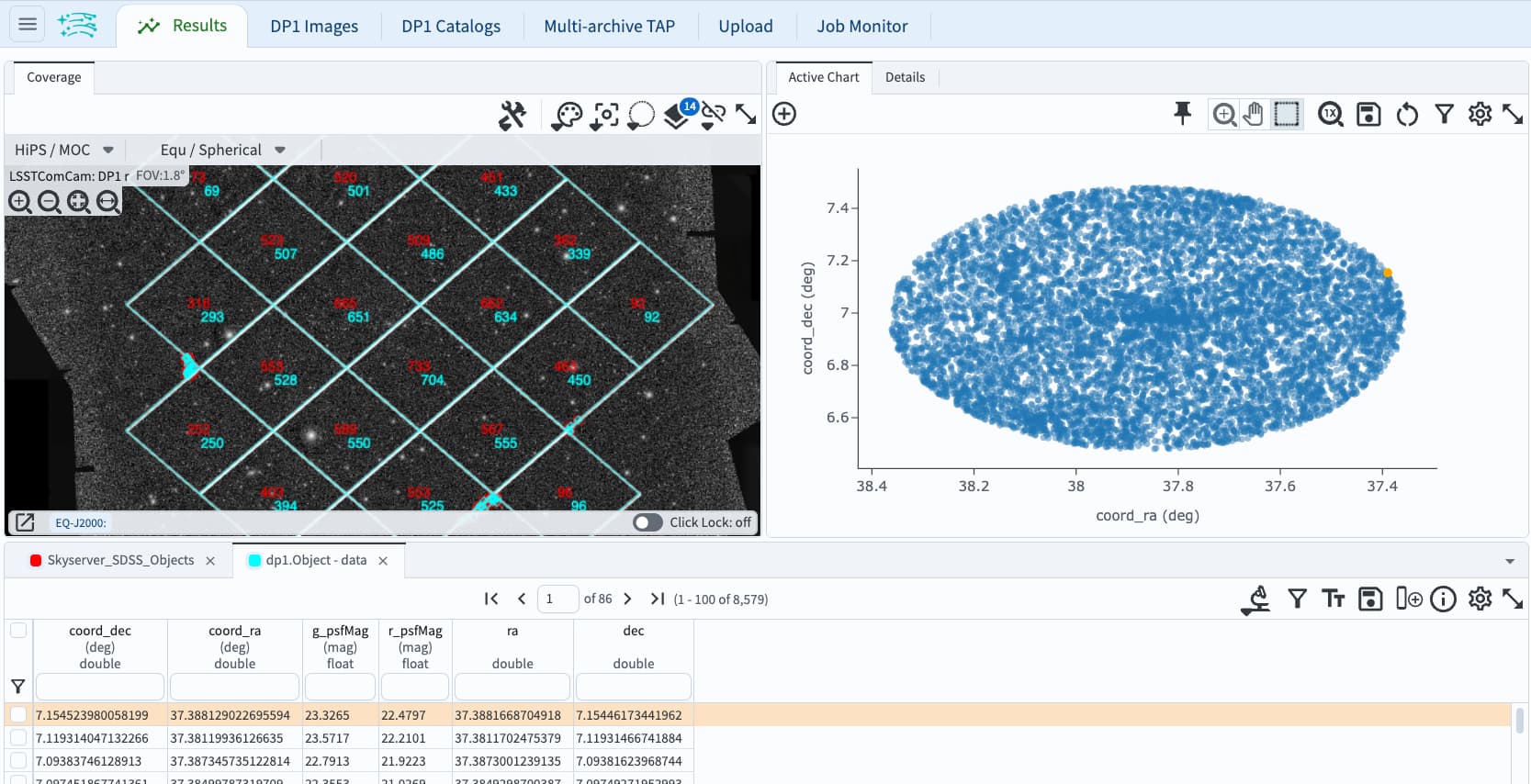
Hi again, I was curious to try this out in a notebook and so I have a python example that I think meets the service you’re looking for?
Set up with the necessary imports and instantiate the RSP TAP service.
from astroquery.sdss import SDSS
from astropy import coordinates as coords
import matplotlib.pyplot as plt
from lsst.rsp import get_tap_service
rsp_tap = get_tap_service("tap")
Query SDSS for objects in the northernmost DP1 field (Low Ecliptic Latitude Field). Columns of type uint64, which is the returned type of the objid column, are not supported in user table uploads, so convert it to a long integer.
pos = coords.SkyCoord('02h31m26s +06d58m48s', frame='icrs')
ut1 = SDSS.query_region(pos, radius='3 arcmin', spectro=False)
ut1['objid'] = ut1['objid'].astype('long')
print(len(ut1))
This returns 896 rows of ut1 (user table 1).
Create the ADQL query statement that will cross match the SDSS table with the DP1 Object table using a match radius of 1 arcsecond. Submit they query to the RSP TAP service and retrieve the results.
query = """
SELECT objectId, coord_ra, coord_dec,
ut1.ra AS ut1_ra, ut1.dec AS ut1_dec, ut1.objid AS ut1_objid
FROM dp1.Object, TAP_UPLOAD.ut1 AS ut1
WHERE CONTAINS(POINT('ICRS', coord_ra, coord_dec),
CIRCLE('ICRS', ut1.ra, ut1.dec, 0.00027))=1
ORDER BY coord_ra ASC
"""
job = rsp_tap.submit_job(query, uploads={"ut1": ut1})
job.run()
job.wait(phases=['COMPLETED', 'ERROR'])
print('Job phase is', job.phase)
if job.phase == 'ERROR':
job.raise_if_error()
assert job.phase == 'COMPLETED'
results = job.fetch_result()
print(len(results))
This returns a match result of 789.
Make a plot to visualize matches:
plt.plot(ut1['ra'], ut1['dec'], 'o', mew=0, alpha=0.5)
plt.plot(results['coord_ra'], results['coord_dec'], '+', color='black')
plt.show()
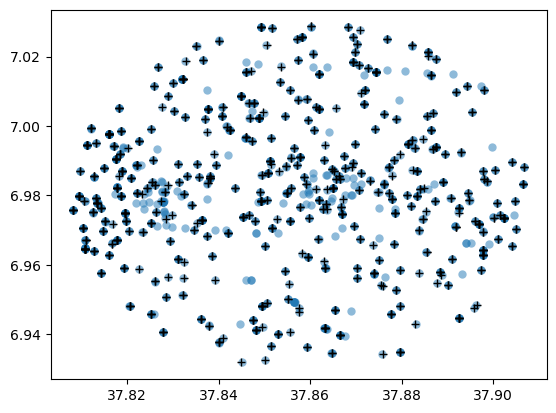
If this is what you were looking for, can you mark this post as the solution? If not that’s ok! We can continue to discuss.