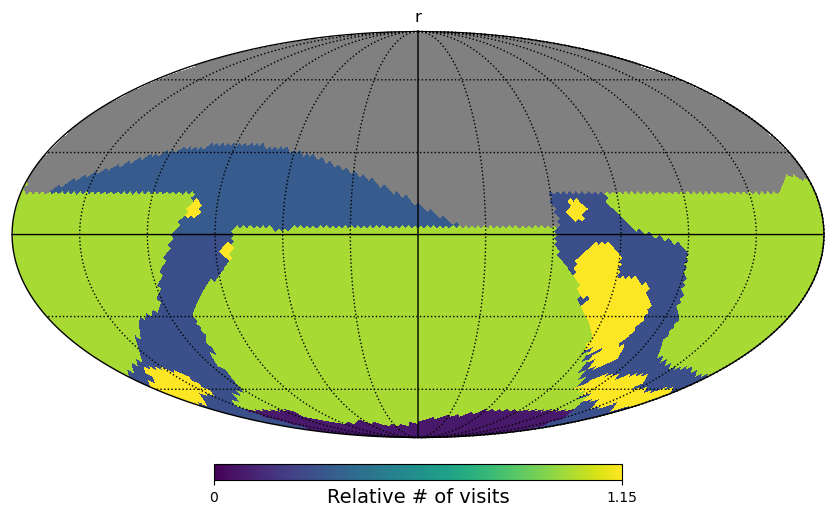
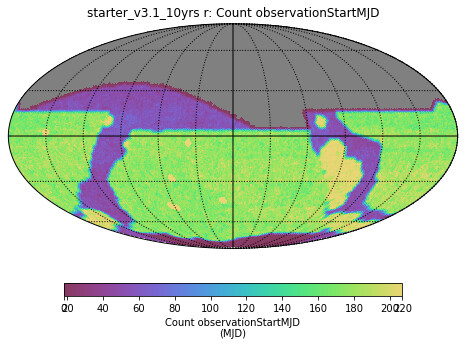
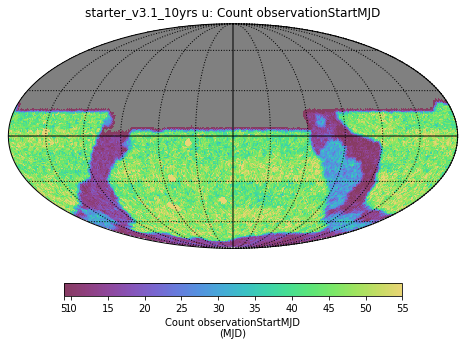
I’m asking this question on behalf of someone else in the community who’s working on Roman: if somebody wanted to start making data products or plan future data products so as to be coadded onto footprints that match what LSST data releases will use, would this currently be possible? Has the exact choice of LSST data release coadd tiling been finalized/decided yet?
I know the LSST pipelines skymap concept is configurable, so one experiment I did was to run butler register-skymap with all default config parameters, generating the attached pickle object and printouts appended at bottom of this message. But I don’t know if it’s safe to assume that the default-parameter skymap is what LSST data releases will actually adopt.
@sfu also pointed me to the makeSkyMap config file within the obs_lsst package, so maybe that’s the answer?
Thanks very much.
printouts
pipe.tasks.script.registerSkymap INFO: sky map has 12 tracts
pipe.tasks.script.registerSkymap INFO: tract 0 has corners (35.576, 13.571), (324.424, 13.571), (261.130, 56.421), (98.870, 56.421) (RA, Dec deg) and 350 x 334 patches
pipe.tasks.script.registerSkymap INFO: tract 1 has corners (155.576, 13.571), (84.424, 13.571), (21.130, 56.421), (218.870, 56.421) (RA, Dec deg) and 350 x 334 patches
pipe.tasks.script.registerSkymap INFO: tract 2 has corners (275.576, 13.571), (204.424, 13.571), (141.130, 56.421), (338.870, 56.421) (RA, Dec deg) and 350 x 334 patches
pipe.tasks.script.registerSkymap INFO: tract 3 has corners (97.175, -20.621), (22.825, -20.621), (11.988, 42.674), (108.012, 42.674) (RA, Dec deg) and 350 x 334 patches
pipe.tasks.script.registerSkymap INFO: tract 4 has corners (217.175, -20.621), (142.825, -20.621), (131.988, 42.674), (228.012, 42.674) (RA, Dec deg) and 350 x 334 patches
pipe.tasks.script.registerSkymap INFO: tract 5 has corners (337.175, -20.621), (262.825, -20.621), (251.988, 42.674), (348.012, 42.674) (RA, Dec deg) and 350 x 334 patches
pipe.tasks.script.registerSkymap INFO: tract 6 has corners (48.012, -42.674), (311.988, -42.674), (322.825, 20.621), (37.175, 20.621) (RA, Dec deg) and 350 x 334 patches
pipe.tasks.script.registerSkymap INFO: tract 7 has corners (168.012, -42.674), (71.988, -42.674), (82.825, 20.621), (157.175, 20.621) (RA, Dec deg) and 350 x 334 patches
pipe.tasks.script.registerSkymap INFO: tract 8 has corners (288.012, -42.674), (191.988, -42.674), (202.825, 20.621), (277.175, 20.621) (RA, Dec deg) and 350 x 334 patches
pipe.tasks.script.registerSkymap INFO: tract 9 has corners (158.870, -56.421), (321.130, -56.421), (24.424, -13.571), (95.576, -13.571) (RA, Dec deg) and 350 x 334 patches
pipe.tasks.script.registerSkymap INFO: tract 10 has corners (278.870, -56.421), (81.130, -56.421), (144.424, -13.571), (215.576, -13.571) (RA, Dec deg) and 350 x 334 patches
pipe.tasks.script.registerSkymap INFO: tract 11 has corners (38.870, -56.421), (201.130, -56.421), (264.424, -13.571), (335.576, -13.571) (RA, Dec deg) and 350 x 334 patches
skyMap_test_skymaps.pickle (1.0 KB)