Thanks for providing sample alerts - they are useful to start preparing brokers for LSST! I would like to give a feedback on the cutouts. For reference, I was mainly working with latest_single_ccd_sample.avro (as of 2020/07/20).
raw cutouts -> gzipped cutouts
I noticed the cutouts are plain FITS file (i.e. uncompressed). While this is explicitly stated in LSE-163 (section 3.5.1), is there any chance to compress the data in the future? I made some statistics on the size of objects without and with compression (gzip), and the gain in space for each alert would be between 20 and 30%.
huge cutouts
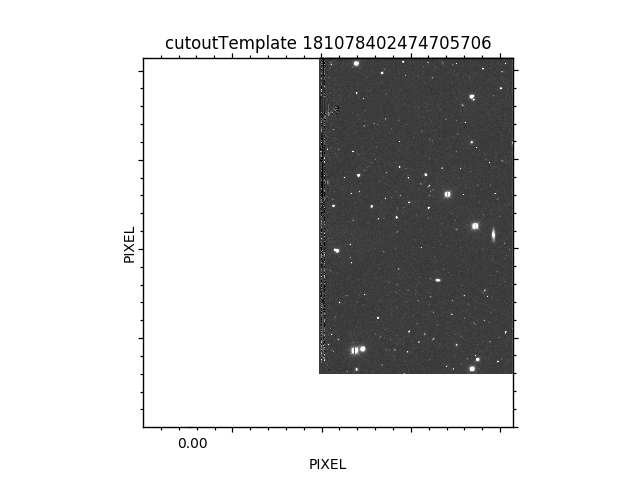
There are a few cutouts for which the size is very large (several MB). Here is the list of of alertId with the two cutouts above 5MB:
181078402474705706
181078402474705741
181078402474705748
181078402474705752
181078402474705769
I visually inspect these cutouts, and they do not look like cutouts but rather a large part of a CCD, e.g.:
Some detections on bleed trails or other artifacts generate
extremely large footprints and correspondingly large cutouts.
We expect to mitigate this problem in the future.
this might explain the large cutouts found above, although I do not see obvious artifacts there.
EDIT: I just noticed that the data has changed (https://github.com/lsst-dm/sample_alert_info/blob/master/CHANGELOG.md#2020-07-15), and the new release of latest_single_ccd_sample.avro does not contain such a large cutouts anymore (with the file last modified on 2020-07-22 11:43 ). I can see cutouts with moderate size (~2MB), but they are associated with artifacts, like
which seems to be something known and expected by the DM team. Hence my original question focuses now only on the possible data compression.
Yes, it is likely we will gzip-compress the image cutouts in the future, probably by gzipping the entire cutout. (For small cutout sizes, the text FITS headers present a significant overhead.)
As to the large cutouts, these are the result of a number of goals. The DPDD (section 3.5.1) requires us to send the full detection footprint–which for artifacts like the one above can be quite large. (This also uncovered some bugs which erroneously generated extremely large footprints.)
It also seemed initially reasonable to require the cutouts to be square and to center the DIASource in the middle of the cutout–those decisions lead to the large empty areas you are showing above.
There are science cases for large cutouts, though: some streaking Near-Earth Asteroids can be as long as 0.5 degrees in 30 second exposures…
We’re continuing to test and improve the cutout generation; your feedback on what will be the most useful for your goals will be helpful.
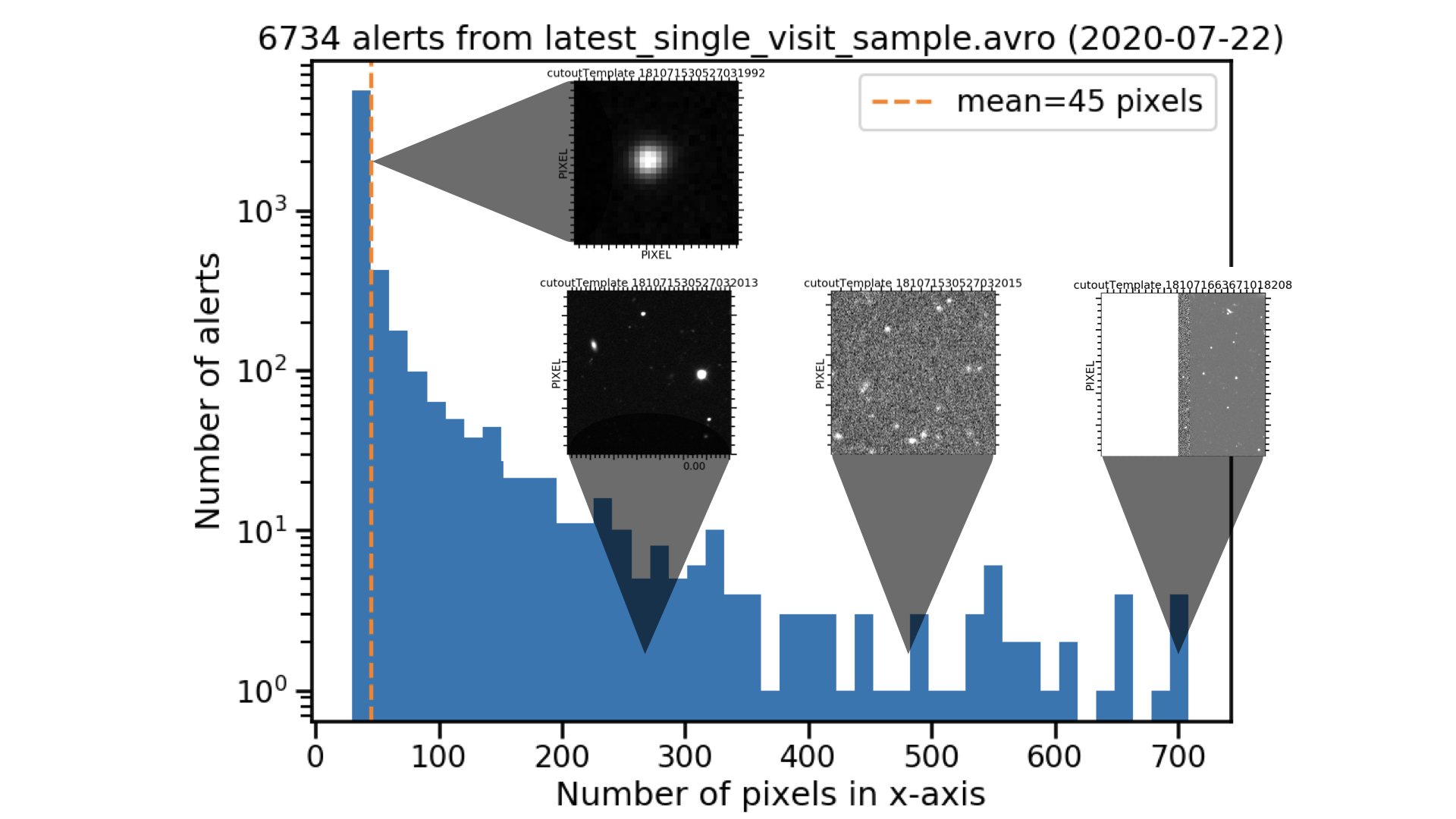
I did not realize the constraints from the DPDD on the cutout size is a “no smaller than” rather than a fixed size. For reference, I plotted the distribution of cutout sizes in pixels, with some typical cutouts highlighted (from latest_single_visit_sample.avro):
while the mean (45pix) is around the smallest size (30pix), one has a long tail with large alert packets. I’ll continue to explore the data and send feedback.
FITS header compression has been discussed in the past both by the FPACK authors (Pence, White, & Seaman) and by the FITS technical working group. The default FPACK Rice compression outperforms gzip in compression ratio and speed for both lossless and lossy regimes applied to the pixels. It has always been recognized that use cases involving numerous small cutouts could benefit most from a native FITS header compression convention, otherwise the readable headers are a desirable feature. (A review of what FITS keywords are required might be the most efficient way to reduce the size of the header.)
Compression should be viewed in a larger context than just storage space (see links from fpack Home Page). Speed issues, both of compression / decompression, and for alerts of a multi-hop network transport timing budget, are at least as important. Indeed, remaining uncompressed is often an attractive option operationally, for instance if these cutouts will be repeatedly processed by brokers. If some fraction of the cutouts are significantly larger than the rest, they might be FITS tile-compressed leaving the rest uncompressed. That way all cutouts remain conforming FITS and libraries like CFITSIO can access the tiles efficiently.
If header compression remains of interest, there are a couple of basic options (with variations under the hood): 1) a legal FITS file can already be constructed by transforming the header keywords into a bintable and FPACK-compressing the table, and 2) it would be relatively trivial to gzip the fz-annotated header records concatenated with the Rice-compressed data records. Note the economies of scale from aggregating MEF headers into a single bintable.
LSST could also raise the issue of a header compression convention at the FITS BoF at the upcoming ADASS (or rather, raise the issue now and resolve it then). If higher compression ratios are required, one of these options combined with aggressive lossy FPACK compression could likely realize 10:1 or better ratios. The fundamental tradeoffs are in juggling both low-entropy headers and high-entropy pixels using the same toolkit.