Tracts and patches are areas on the sky, not areas of the focal plane.
The focal plane is divided into detectors (CCDs) for processing purposes. There are also amplifiers (sometimes called channels) within a detector for specialized purposes, and for other specialized purposes LSSTCam detectors are grouped into so-called “REBs” and “rafts”, but they don’t usually appear in processing.
The sky, on the other hand, is divided into potentially hundreds of tracts (which overlap at their edges) and each tract is divided into patches. The positions, shapes, and distribution of these tracts and patches depend on the skymap chosen, which often depends on the particular survey.
Each tract and patch will be observed by many different detectors at different times. Patches and detectors do not align with each other in any way; the size of a patch may be bigger or smaller than a detector, may be offset from the area a detector views, and may be rotated with respect to a detector in any given image.
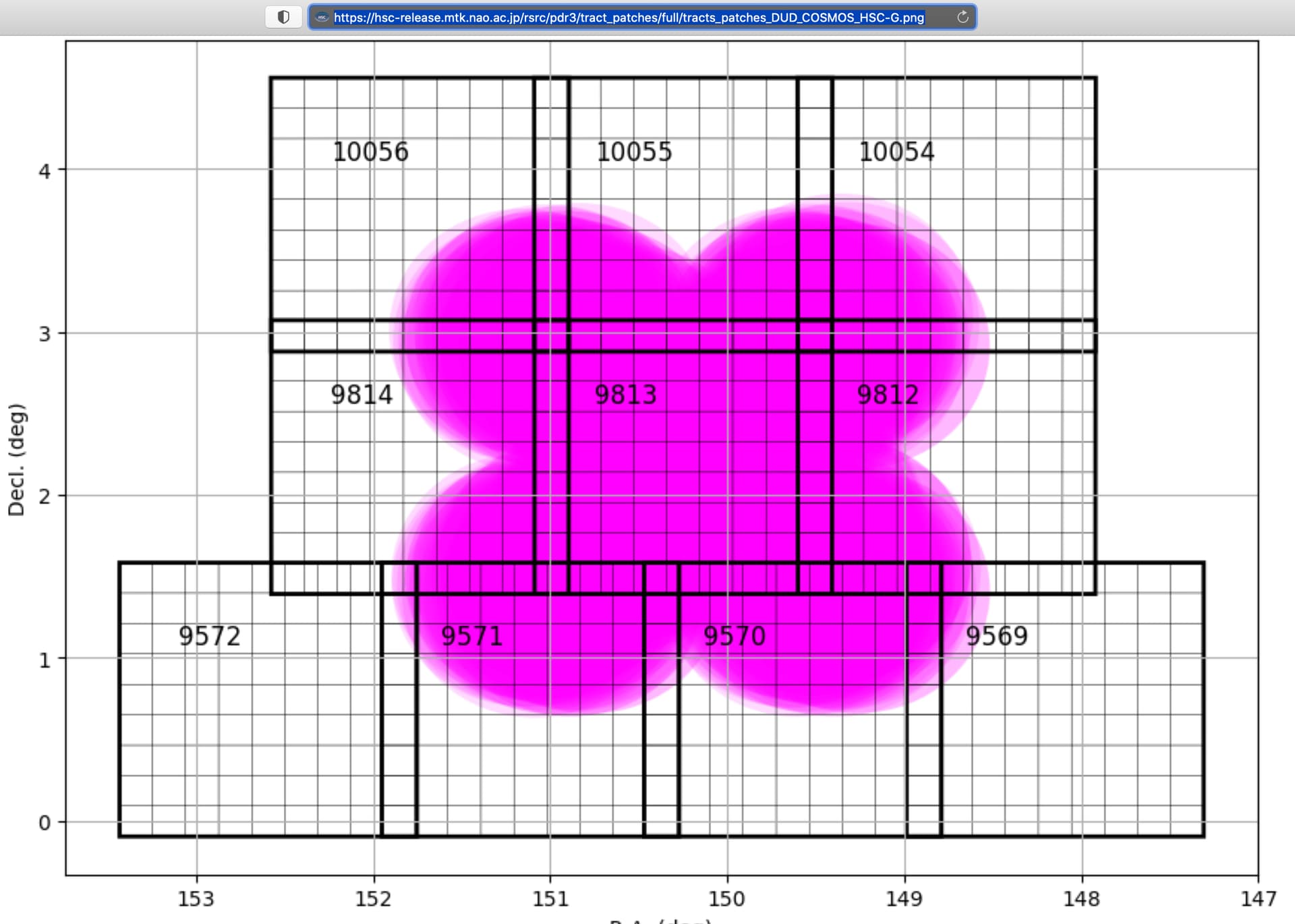
Thank you VERY much KTL. Your comments affirm what I’ve been gleaning from the documentation on the HSC website. Literally, 10 minutes ago, I realized what you said…that tracts correlate to the sky, not the CCD/detectors. Amazing. For example, tract 9813 in our gen3 tutorial points to objects at RA/DEC of 150/2.2. I found tract 9813 of the HSC Cosmos field is also centered around RA/DEC of 150/2.2. Bingo, the light finally went on. Man, thanks. Below is one of the graphics from HSC that is a great example for me.
I wish the docs I’ve been digging through were as clear as your explanation. One statement does the magic " Tracts correlate to the sky; Tracts are further divided into 9X9 patches…etc…".
In the gen3 tutorial, do you know if there is a query that would show me ALL the distinct tracts and the part of the sky that they correlate with. Part of me wants to expect that this is a universal standard…but I should rejoice in what I realized so far.
thanks again.
Fred, Dallas
KTL, my further reading on the HSC pipeline at https://arxiv.org/pdf/1705.06766.pdf yielded this comment about the HSC tracts: While the pipeline itself allows essentially arbitrary tract definitions, SSP productions use a variant of the rings sky tessellation initially developed by the Pan-STARRS team (Waters et al. 2016), which splits the sky into a number of constant- declination rings (120, in our case).
So, I conclude that HSC defines 120 “rings” that correlate to the observable sky above the HSC platform in Hawaii.
And, that LSST may have a similar nnn “rings” that correlate to the observable sky above the LSST site at El Penon.
…Hoping I’ve got this reasonable correct.
thanks, Fred, Dallas
No. Skymaps are defined independently of the observatory. If we use the hsc_rings skymap definition for LSSTCam data we would end up with final coadded images that will use the same tract/patch definitions. Skymaps are partitioning the whole sky and don’t care about the specific location of a telescope.
Thanks. The skymap employed by a given telescope would only define a portion of the “whole” sky accessible to the instrument…kinda like the skymap registry table in gen3 tutorial.
What I’m getting at Tim:
1. Is the skymap a universal standard for professional astronomy.
2. Ergo, is there a standard set of pre-defined Tracts/patches for professional astronomy that further define the Skymap.
thanks, Fred, Dallas
Usually not. Usually you would define the skymap for the entire sky but there won’t be any data in the tracts that a particular instrument can’t see.
No. Each group can decide to break up the sky how they see fit. We use tangent plane projections with overlap to minimize distortions (if you are analyzing point spread functions of stars you want to do that in a fairly flat coordinate system). Depending on your needs you can choose different skymaps. Some surveys use HEALPix and that is especially useful for all-sky visualizations – the IVOA HiPS standard makes use of that. The downside being that at the vertices of the grid you can get interesting distortions. Converting a sphere into pixel grids is hard though and there are many ways to do it.
No. Even with the sky ring skymap we use for HSC someone could decide that they want smaller tracts if they wanted or different numbers of patches per tract. It’s driven by the specific needs – if you want to combine your data with that from another instrument it makes a lot of sense to pick a matching skymap since you get easy alignment but you also have to think about the pixel size you use and that depends on the size of your PSF which depends on seeing and telescope size.
Great explanation as usual. I thought about distortions after I sent my last questions. I’m realizing that some aspects of the pipeline cannot be completely realized when my myopic view is governed by the gen3 registry and related tables/fits files. Thankful for you and community for helping me fill in the gaps…
for example:
sqlite> select * from skymap;
name hash tract_max patch_nx_max patch_ny_max
Tim,
Can you advise where I can read the tech. doc for this part of the process. I’ve explored the /lsst_stack/ tree for my gen3 install, not sure where the tech. doc may be. Or, a link to wherever I can find it.
Many thanks,
Fred, Dallas
Tim, I did find the WCS utils in the lsst stack. I’m wondering if the Gen3 tutorial part 5 is where this the tangent plane projections takes place (i.e. “warping” images onto the skymap). Do you agree?
thanks, Fred, Dallas
I’m trying to use the function named checkManagersVersions from the Class ButlerVersionsManager , and I am seeking documentation and examples.
I’m at the Gen3 stack tree:
eups list lsst_distrib
22.0.1-3-g7ae64ea+34933a78b0 current w_2021_37 w_latest setup
This Class in defined in the versions.py located in the %/lsst/daf/butler/registry/ path. I thought I would find docs at URL: lsst.daf.butler — LSST Science Pipelines
Can you please help, or suggest what I’m doing wrong here?
Many thanks, happy holidays,
Fred from Dallas
These are internal administrative APIs and we weren’t expecting people to be wanting to read the sphinx documentation. You can read the documentation with pydoc lsst.daf.butler.registry.versions.
These classes are used to allow the registry to check that the correct plugin versions are being used. Are you wanting the documentation out of general interest or because you want to be able to use the class?
okay, Tim. Can you send me an actual pydoc link to access this documentation. When I scroll through the link lsst.daf.butler — LSST Science Pipelines , I can’t find the .versions .
I want to use this function to list the manager versions programmatically; as you know, a few examples do show a lot of information. That’s why I was seeking a few examples.
Anyway, your upline question is relevant; I ran this butler command: butler --log-level DEBUG --long-log --log-tty query-data-ids SMALL_HSC --collections HSC/RC2/defaults --datasets ‘raw’ --where "instrument=‘HSC’ AND detector=41 AND band=‘y’ AND exposure=322"
The log showed: DEBUG 2021-12-29T18:02:53.201-06:00 lsst.daf.butler.registry.versions ()(versions.py:320) - found manager version version:lsst.daf.butler.registry.attributes.DefaultButlerAttributeManager=1.0.0, current version 1.0.0
So, I attempted to recreate this step independently in a Jupyter notebook, just to affirm my pipeline Python OOP acumen.
So, that’s the origin of my question. The challenge that I face is that without examples I have to dig to understand what some of the parms/objects consist of in order to reconstruct an isolated execution of the process.
Sidebar question … I installed gen3 in October. I wish to update it again before I rerun the pipeline exercises, including many jupyter notebook sidebar exercises of my own.
Here is what I show: $eups list lsst_distrib 22.0.1-3-g7ae64ea+34933a78b0 current w_2021_37 w_latest setup
Can you pls affirm the step I can execute to just update my lsst stack tree to the latest, like this?: eups distrib install -t w_latest lsst_distrib # This will install 82+ packages eups distrib install -t v22_0_0 lsst_distrib # We’re not still at 22, I expect…
…or do you recommend that I just start over…
Happy new year.
Go Webb…
Fred, Dallas
pydoc is what you type locally on your unix shell. It’s a standard python command for reading class documentation. If you are at a python prompt you can do:
>>> import lsst.daf.butler.registry.versions as versions
>>> help(versions.ButlerVersionsManager)
and it will show you it. That will work in a Jupyter notebook as well. You can use help with any python functions or class.
Your eups distrib install lines are fine and you should definitely use weeklies for gen3 exploration. v22 is ancient and is far too old for up to date playing with gen3. v23 will be out in January but it’s already 3 months old.
You will need a new conda rubin-env – unless you want to be able to switch between w37 and the latest in the same shell (which will have problems with python dependencies anyhow) you may as well install a fresh version of the software from scratch.
okay, did not realize the pydoc command was local. Yes, I’ve been doing imports and help(), dir(), inspect() forever…I’m totally familiar with these for sure for years. I thought there may be a link to a more formal LSST doc library via a link. Something a bit more than one sentence with no examples. I thought this would lead me somewhere, but not sure: https://ls.st
Repeating myself, from upline comment, but why should I not be able to see the lsst.daf.butler.registry.versions docs with this link: lsst.daf.butler — LSST Science Pipelines ?..am I missing something along the way here. Or perhaps this is not available to the community forum…just the delegates.
…on the restart question, I believe I’ll take your suggestion and archive what I have and start over. I’ve been through the pipeline two full times now in intermediate level detail with logging, etc., absorbing a lot , again, thanks to your help.
Thanks again,
Fred, Dallas
https://ls.st is a link-shortener. It is not an index of documentation. You may be thinking of https://www.lsst.io/ which is an index of our (generally hand-written) prose documents.
For classes that are not exported by default we have to write an explicit line into the sphinx documentation templates to make them visible. For internal APIs this is not something we think about much because we can get the documentation very easily without using Sphinx (using the source code, or pydoc etc). There is no rule against us including those classes in the build documentation and we can try to do so in future – we would have to be clear that we are not required to meet the same demands on backwards compatibility for these APIs if we were to include them in the build.
thanks Tim, I’ve probably already pushed the doc question too much. I’ve already absorbed a lot from docushare for lsst, such as: https://docushare.lsst.org/docushare/dsweb/Get/LSE-163
…perhaps I was expecting something equivalent at the Class level. Like you, and everyone, I’ve become pretty good at gleaning things from the code…even though it’s a struggle at the beginning with new system.
have a safe New Years celebration.