Hi,
I would like to run MakeDiscreteSkyMapTask as part of a gen3 pipeline after creating calexp datasets. I am using the latest stack release. All calexps should be used to produce a single skymap. I understand there is a butler client tool for this, but I want to use it in a pipeline.
Doing this out of the box is presently not possible (I believe) because the task is not written / configured for gen3 pipeline use. I have therefore written the following code:
from lsst.pipe.tasks import makeDiscreteSkyMap as taskBase
DIMENSIONS = ("skymap",)
TEMPLATES = {"calexpType": ""}
class MakeDiscreteSkyMapConnections(pipeBase.PipelineTaskConnections,
dimensions=DIMENSIONS,
defaultTemplates=TEMPLATES):
# Based on lsst.pipe.tasks.makeCoaddTempExp
calExpList = cT.Input(
doc="Input exposures to be covered by the output skyMap.",
name="{calexpType}calexp",
storageClass="ExposureF",
dimensions=("instrument", "visit", "detector"),
multiple=True,
deferLoad=True,
)
# Based on lsst.skymap.baseSkyMap
skyMap = cT.Output(
name="skyMap",
doc="The sky map divided into tracts and patches.",
dimensions=["skymap"],
storageClass="SkyMap"
)
class MakeDiscreteSkyMapConfig(pipeBase.PipelineTaskConfig, taskBase.MakeDiscreteSkyMapConfig,
pipelineConnections=MakeDiscreteSkyMapConnections):
pass
class MakeDiscreteSkyMapTask(taskBase.MakeDiscreteSkyMapTask):
ConfigClass = MakeDiscreteSkyMapConfig
def runQuantum(self, butlerQC, inputRefs, outputRefs):
"""
"""
inputs = butlerQC.get(inputRefs)
# Organise inputs to what the base task needs
wcs_md_tuple_list = []
for calexp in inputs["calExpList"]:
wcs = calexp.getWcs()
md = calexp.getMetadata()
wcs_md_tuple_list.append((wcs, md))
# Run the task
outputs = self.run(wcs_md_tuple_list)
# Use butler to store the outputs
butlerQC.put(outputs, outputRefs)
The simplified / problematic quantum graph looks like this:
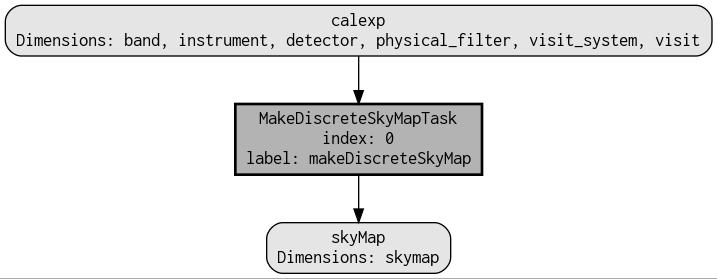
I run the task in an existing butler repository:
pipetask run -b ${REPO} -t huntsman.drp.lsst.tasks.makeDiscreteSkyMap.MakeDiscreteSkyMapTask --input calexp/20210720T034253Z --output skymap --register-dataset-types
This results in the RuntimeError: QuantumGraph is empty error. I have read the FAQ about this but found no solution.
Running butler query-datasets ${REPO} --collections calexp/20210720T034253Z shows that the calexp datasets do exist.
I do however notice this warning:
SAWarning: SELECT statement has a cartesian product between FROM element(s) "skymap" and FROM element "physical_filter". Apply join condition(s) between each element to resolve.
I do not know how to resolve this issue. A workaround would be to split the pipeline into two parts and manually create the skyMap in between, but this is not ideal and should not be necessary.
Any pointers on this would be much appreciated! Apologies if this has already been asked, I have searched the community forum with no luck.