The v2.1 simulations include a focused dive into Deep Drilling Field scheduling, with a series of different options in ddf scheduling options, as well as refinements on the galactic plane coverage, options regarding ensuring ‘good seeing’ images in different bandpasses, and a variety of other smaller investigations. These simulations are intended to be considered in concert with the v2.0 simulations (announced here).
The v2.0 and v2.1 simulations are described in more detail in the SummaryInfo_v2.1 notebook, but a brief description of the questions addressed include:
varying the extent of rolling cadence
varying the intra-night cadence (triplets or pairs, what kind of separation between visits)
varying the coverage of the Northern Ecliptic Spur region
varying the coverage of the galactic plane (non-bulge) region, as well as the footprint of coverage within the galactic plane
varying the exposure time in u band and the number of bluer (u and/or g) band visits (relating to filter balance)
varying the exposure time
varying the number of ‘good seeing’ images required in various bands in each year. Note that v2.1 adds ‘good seeing’ images in r and i bands each year by default (baseline_v2.1_10yrs).
investigating the effect of suppressing repeat visits within each night, beyond the original pair (we found that about 10% of nights have more than a single pair of visits in the baseline)
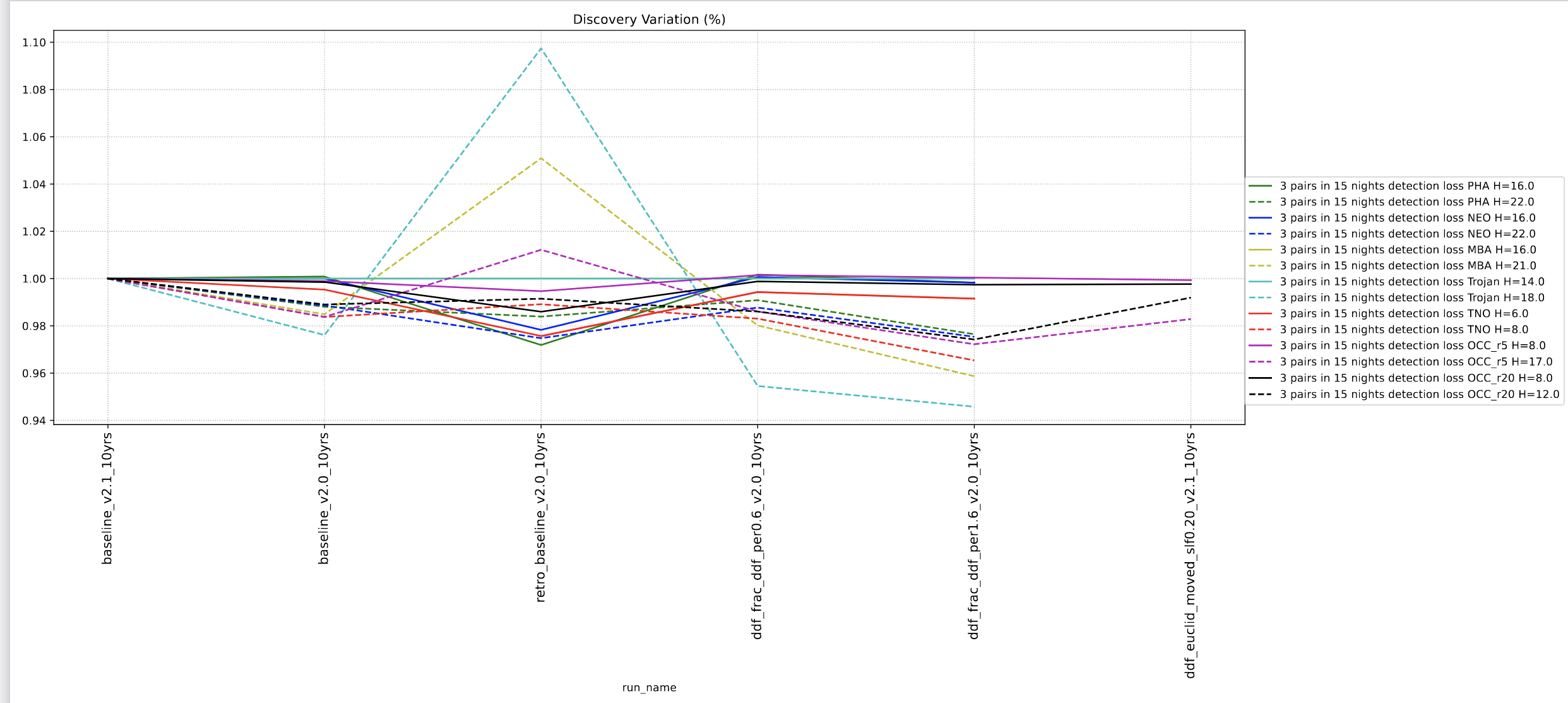
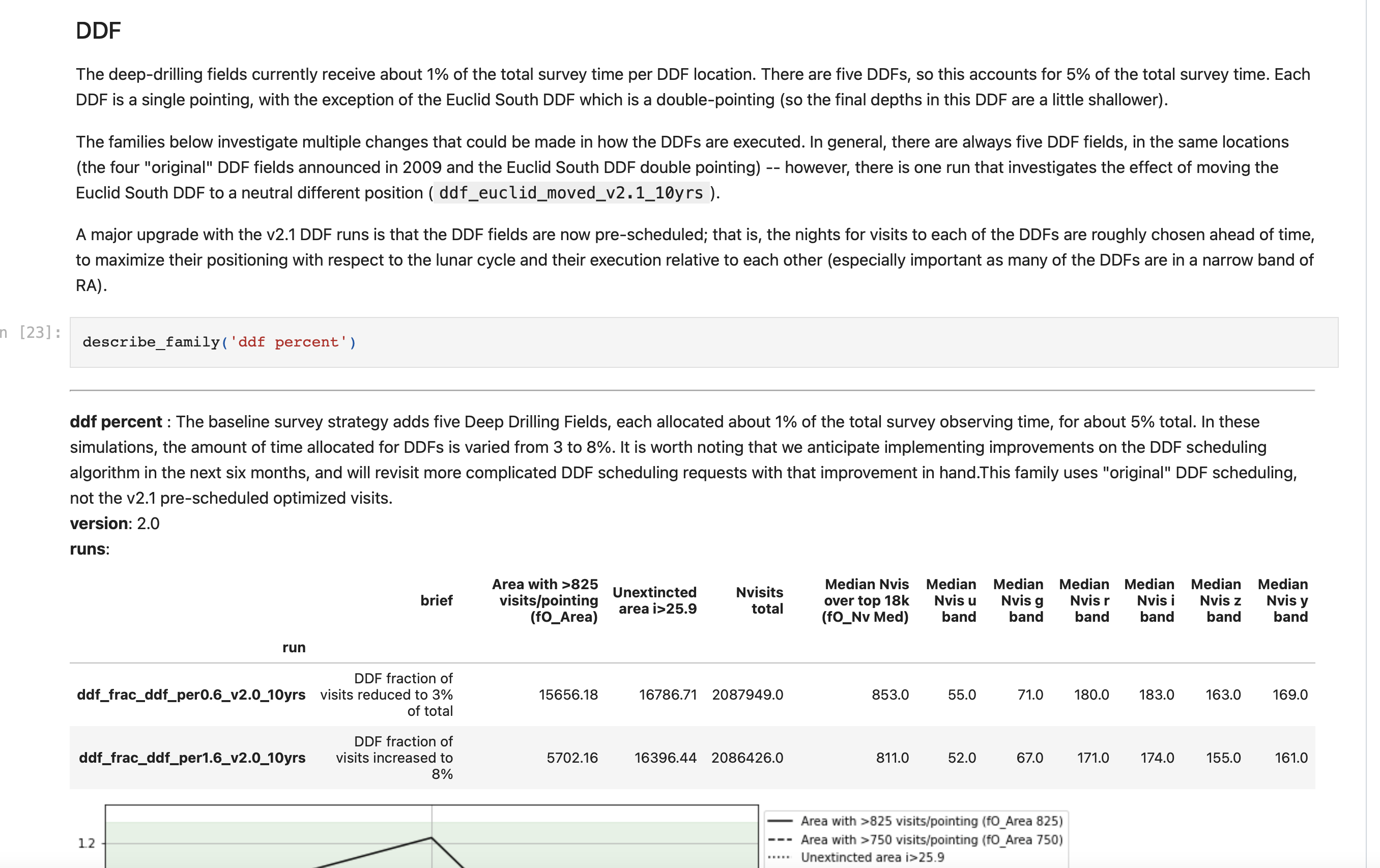
varying the amount of time spent in Deep Drilling Fields, as well as their cadence. Notably, the v2.1 runs introduce a new method of planning DDF visits that pre-schedules the visits to take the best advantage of the lunar cycle … in a variety of versions, explored in the various ddf families.
microsurveys, where additional small special projects are added to the simulation in v2.0:
Extending the WFD to cover the Virgo cluster – note that this was so low-impact to the remainder of the survey and such a slight modification to the WFD region, that it was added to the baseline in v2.1 (baseline_v2.1_10yrs).
ToOs for GW optical counterparts - these ToO observations are intended to show the general impact of ToOs, however the plan for coverage is still evolving.
Twilight NEO discovery visits - these will need another round of simulations, to conform with constraints on the camera shutter rate.
Short (1-5 second) exposures over the sky
Coordinated observing of the Roman microlensing bulge field
Limited coverage of a northern stripe not otherwise observed, up to Dec=+30
High cadence visits to the SMC
The v2.0 and v2.1 simulations include 265 runs.
The MAF analysis of these simulations is available at http://astro-lsst-01.astro.washington.edu:8080/
In general, the MAF analysis outputs are split into subsets to aid in finding particular ‘kinds’ of metric outputs:
the “Science” category (‘mafComment = Science’) contains primarily metrics that are higher-level science-focused; many of these are the metrics contributed by the community
the “SSO” category contains metrics focused on solar system science; these would be in the Science category, except that we generate them separately so they get their own separate page
the “DDF” category is only available for some of the runs, but contains metrics focused on DDF visits; these are particularly useful for the DDF family simulations
the “Metadata” category contains metric outputs that describe primarily basic details about the observations and how they were taken - things like the airmass distribution, coadded depths, intra-night visit gaps, etc.
The summary statistics computed for each of these metrics is shown with the metrics, but also collected into a big CSV file which can be found here - summary_2022_04_28.csv
The CSV file can be used, optionally together with the runs_v2.1.json file and the metric_sets.json to investigate the families of simulations - see this example tutorial or this demo (and others in this same repo) to see how to use these files with some tools from MAF to investigate the outputs of these runs.
We didn’t run the solar system metrics for every DDF simulation. There are so many of them and we didn’t expect significant variations in solar system metrics when the overall amount of DDF time was held constant.
I thought they were run for the euclid_moved simulation though, so I’ll double check on that.
Thanks for clarifying @ljones . That makes sense. When there’s a final version of the v2.0-v2.1 csv file will it be zenodo-ed so there’s a permanent copy that can be cited in cadence papers for theAAS journals LSST cadence focus issue?
Also it would be helpful if the summary jupyter notebooks for 1.5/1.7, and 2.0/2.1 could also be given zenodo DOI links. I was sitting in an online workshop of reproducible science and it was pointed out that this is a good idea since it means that folks can accurately cite the notebooks and it lives on if the repo with the notebook ever changed or was removed. See Guidance for AGU Authors - Jupyter Notebooks | Zenodo
This would help myself and hopefully others writing additional papers can cite the notebooks which have been so helpful and they would be preserved for time.
Meg, these are great questions.
We have no control over the data storage at NOIRlab, although we hope they will continue to provide these databases as part of the copute facilities. We also can’t control exactly where NCSA hosts the output databases, although it is relatively stable and I think is where I’d say it’s most likely to continue to be so (where you can download the outputs from Index of /sim-data). The UW links to download the databases at Index of /~lynnej/opsim_downloads are dependent on the continued existence of the “epyc” machine. Thanks for making me think a little more about this, though – I suspect the only place we can guarantee permanent storage is in the LSST Docushare, so I will see if I can upload copies there.
We can add zenodo links for the various summary info notebooks (I think this is what you mean?) but we did not build these outputs with the idea of them being permanent references and so some of the links contained in the notebooks do change (primarily - what we host on astro-lsst-01.astro.washington.edu:8080 is the current set of simulations under consideration, and we put the previous set on astro-lsst-01.astro.washington.edu:8081). The DNS is not permanent: if astro-lsst-01 (our machine at UW hosting these resources) were to fail, I don’t think we’d be guaranteed to have a new host with the same name.
I’d prefer to wait until we’ve gone through a round of consultation with the community on the current set of notebooks and summary CSV files … there are things we don’t notice being incorrect or missing until looking more closely with the community, for example. But yes, it’s a good idea to add a zenodo version of those outputs.
We can add zenodo links for the various summary info notebooks (I think this is what you mean?) but we did not build these outputs with the idea of them being permanent references and so some of the links contained in the notebooks do change (primarily - what we host on astro-lsst-01.astro.washington.edu:8080 is the current set of simulations under consideration, and we put the previous set on astro-lsst-01.astro.washington.edu:8081).
Yes. That’s what I meant. With the summary notebooks, they might not work any more because links to the data files might not work, but at least the reader could see what content was in the notebook in 5 -10 years if it is in Zenodo. I don’t think you have to promise they run, but that at least someone can open the notebook and read through the descriptions of the simulations and look at the plots. My concern is for some reason that github repo is removed, those notebooks are lost in the long term, and the community is all using them to understand what each simulation is. Also if we’re all using this as a reference, we should cite a permanent version of it.
The problem of continually waiting is that if I write a paper and submit it in July then I have to cite a github url. With Zenodo you can update versions so all that information of revisions is tracked.
Which DOI should I use in citations?
You should normally always use the DOI for the specific version of your record in citations. This is to ensure that other researchers can access the exact research artefact you used for reproducibility. By default, Zenodo uses the specific version to generate citations.
You can use the Concept DOI representing all versions in citations when it is desirable to cite an evolving research artifact, without being specific about the version.
Hi Lynne, I assumed that updating my rubin_sim and then running ‘rs_download_data --force’ would get the new baseline_v2.1 files, but this is not the case, the uploaded data version is always sim_baseline_nov_2021.tgz. What is the simplest way of updating everything in my rubin_sim_data? Thanks!
Actually, I don’t think this is incorrect. It looks like baseline_v2.1_10yrs.db hasn’t been added to the sim_baseline data download yet, so I will go and do that now! Thanks for the heads up.
This is completed - v 0.9.1 of rubin_sim will download a version of the sim_baseline that matches v2.1.
(if you have a pip installation, doing ‘git pull’ , repeating the ‘pip install -e’ command, and then running “rs_download_data --dirs sim_baseline --force” will get your updates.
They are, I’m sorry if it’s confusing.
When we added the v2.1 runs, I took the opportunity to rename and shuffle some of the family names and groupings. I noticed that people were analyzing the presto_* and presto_half_* series separately, and also separately from the long_gaps_nightly* runs. They are distinct configurations, but they address similar questions about how many visits to have per night, and (given the way the rest of our tools for analyzing multiple runs are working), it seemed easier to have these grouped into a larger set of “triplets”.
That is a long way of saying - the ‘ddf_frac’ runs are still there, but now named the “ddf percent” family.
I also renamed the ‘good_seeing’ family “good seeing” and ‘vary_nes’ to “vary nes”, and a few other changes.
If it’s helpful, I can go back and add ‘(previously ddf_frac)’ to the description?
The run names themselves are unchanged.
Thanks. I was wondering if all the Solar System metrics should be run for the ddf season length family . It looks like this family changes the amount of time spent on the DDFs to accommodate the change in season length? It might be instead redistributing out the already dedicated time for DDFs.
I see what you mean. I am not sure if that was the intent of that series, and we should take a closer look.
I do see that the percent of time spent on DDF visits varies across the DDF runs, and in general, I think all of the pre-scheduled DDF runs spent more time on the DDF program than the non-scheduled runs.
I think it’s likely most useful to compare the results of varying the DDF strategy within the DDF family related to that strategy, and then we will likely have to rescale the overall DDF time to match what is currently the standard in the baseline. It does make things a bit more complicated though.
Hi Lynne, thanks for all the work. I just read through this thread and I got to the NCSA server, and I am wondering what the difference is between baseline_v2.2_10yrs.db and no_twilight_neo_v2.2_10yrs.db. Secondly, with the twilight OpSim runs, the format for the file is: twi_neo_repeatM_N_npP*
where M is either 3 or 4
where N is listing filter combinations (z, iz, riz)
and where P is 1-7
giving 42 combinations. The filter options are pretty obvious, but could you please describe the repeat # and the np options, so I can decipher these various setups? I see you posted some of these very recently, so apologies if there is a summary forthcoming.
Hi Nathan,
I’ll add an update to the SummaryInfo_v2.0 (and 2.1 and 2.2 …) notebook shortly, but yes you have it about right for the twi_neo_repeat…
repeat 3 or 4 == attempt three or four visits in each twilight period
N = filter combinations
np 1-7 is ‘night pattern 1-7’ (like in the twilight_neo v2.0 simulations)
As for baseline_v2.2_10yrs.db – please do not use this yet (it’s online, but it may not be our actual “baseline” for v2.2 – we’re still working on those details. the “no_twilight_neo_v2.2_10yrs” run is there to provide a no-twilight NEO visits comparison for these simulations, so you should use that as a comparison point (it is otherwise set up the same as the twilight NEO runs, just not having the twilight NEO micro survey).
This was helpful. I saw your updates to the summary notebook, so thanks for the quick turnaround. I’m a little confused how to think about the no-twilight run as a reference point. Is it a reference point in that all other aspects of it and the various twilight opsims are the same? Is it markedly different the “baseline” runs?
No, it is pretty similar to the baseline runs.
However, one of the things we’ve been adding in v2.1 is pre-scheduled DDF fields, and that will almost certainly be in the baseline_v2.2. However, we haven’t yet decided which version of pre-scheduled DDF to use in the next baseline simulation … so we put one in for the twilight NEO v2.2 runs, but it won’t be finalized yet. Thus you get a “no_twilight” version, to compare against, that includes the same things as the twilight_neo v2.2 runs … and might eventually be the same as the next baseline, but we aren’t sure yet and don’t want to confuse anyone by calling it 'baseline_v2.2" when it may very well not end up being the actual baseline for v2.2.
Thus, compare twilight_neo_v2.2 runs against no_twilight_v2.2 metrics.
(note also that I made a slight tweak in the names of the SSO metrics in the summary stat csv – they are now properly labelled as “completeness XXX H<=Y” instead of “completeness XX H=Y” because they are cumulative completeness values, not differential and thus include H<=Ymag. (and they always were, but I labelled them incorrectly in the summary csv file previously).