I’ve just merged DM-38498 (after w_2023_34 was tagged), which is a complete rewrite of the QuantumGraph generation algorithm. For the most part, you shouldn’t notice much of a difference, but there are a few important exceptions.
And while this has been pretty thoroughly tested - including local runs of rc2_subset and ap_verify as well as all ci_* in Jenkins - a big change like this always carries the risk of unexpected consequences. Please let us know in #dm-middleware-support on Slack (or reply here) if think you see any.
Behavior Changes and new --data-query requirements
The algorithm now looks for independent pipeline subgraphs (groups of tasks that don’t depend on each other) and largely processes them separately, merging them into one quantum graph near the end of the algorithm. Usually this just speeds things up (see benchmarks below), but in rare cases it can change the generated graph, because it means an input-dataset constraint on the data IDs of one task doesn’t apply to unrelated tasks anymore. The only case I’ve seen of this mattering in our current pipelines is in lsst.faro.measurement.TractTableMeasurementTask task, which has band in its quantum dimensions but does not have band in the dimensions of any of their inputs (its only input is objectTable_tract). This leaves the band unconstrained when the task is in a separate QG from the one in which objectTable_tract was produced (as is typical), causing it to attempt to process all bands in the data repository, and fail when it cannot find the corresponding columns in the object table.
While this is unfortunate behavior in this particular case, I believe in general the behavior is actually more intuitive (unrelated tasks shouldn’t affect each other’s quantum graphs). So I’ve updated the documentation for the faro_* steps in drp_tasks and modified the command-lines in rc2_subset, and CM pilots like @eigerx will need to take this into account when running faro in the future.
Raising NoWorkFound in adjustQuantum
PipelineTaskConnections implementations may now raise NoWorkFound in their adjustQuantum methods to prune quanta from the graph when it is first created, with the impacts automatically propagated to downstream tasks. This isn’t as powerful as execution-time pruning using NoWorkFound, because adjustQuantum only has access to the metadata available in data IDs, not the dataset contents themselves, but it can still be used to dramatically reduce quantum graph size in contexts such as DM-37383.
Obsoletion of certain lookupFunction use cases
The quantum graph generation algorithm no longer requires PrerequisiteInput.lookupFunction attributes to be provided in order to deal with a pair of long-standing issues:
-
Tasks (e.g.
jointcal,gbdes) whose quanta have spatial dimensions (e.g.tract) that need reference catalogs covering an area beyond that tract’s extent (e.g. all visits overlapping the tract) can now provide an implementation ofPipelineTaskConnections.getSpatialBoundsConnections()instead. -
Tasks whose quanta do not have temporal dimensions with a prerequisite input for
camera(or other calibration) no longer need alookupFunctionor a special “unbounded” collection at exactly the right spot in the collection search path; they will automatically search for a calibration that is valid over all time, and if they find more than one, only complain then.
Because lookupFunctions still take precedence when they are present, and I have not removed them yet (DM-40500), the new behavior is not yet active, but preliminary results suggest that the new logic will be much faster, as well (see benchmarks below).
Performance Improvements and Benchmarks
The new algorithm is about 2.5x faster than the old one (measured from the total time it takes to build all per-step QGs for HSC RC2), with a lot of variance from step to step:
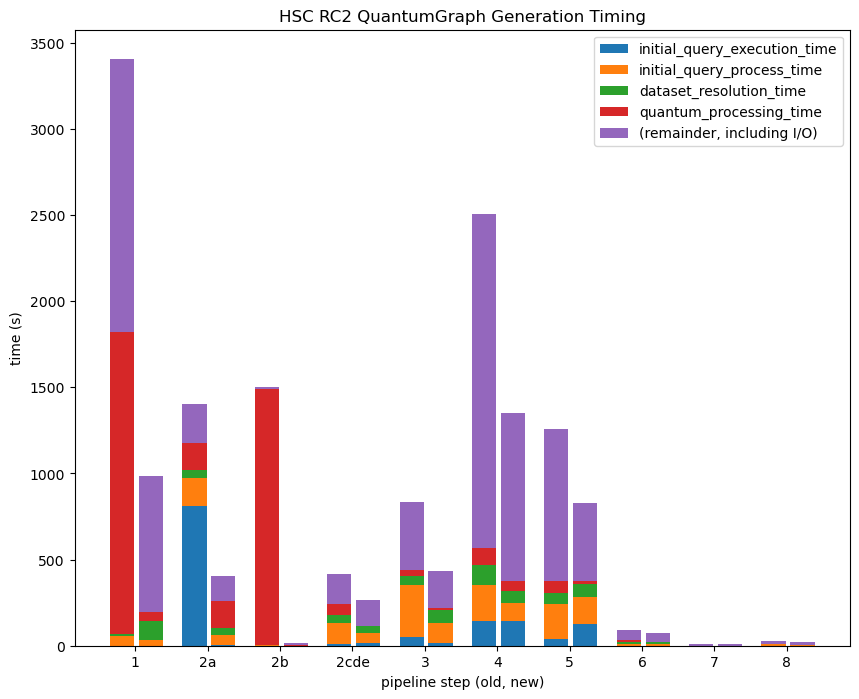
This comes from three separate changes, some of which are far more important for some pipelines than others:
-
Splitting up the pipeline into independent subgraphs can greatly simplify the initial query, making it much less likely that the database chooses a poor query plan. This is most evident in
step2a. -
The most common prerequisite input connections (calibrations and most reference catalogs) are now found using bulk queries over all quanta, instead of many small per-quantum queries (where the per-query latency previously dominated). This is most obvious in
step1, thoughstep2bis quite similar - I’m actually using a DM-40500 branch ofdrp_tasksfor that step (which just runs GBDES), and the dramatic speedup only occurs when thelookupFunctionfor reference catalogs is removed. -
@natelust added some caching to the logic that transforms the in-memory
QuantumGraphto JSON for serialization and tuned the LZMA compression factor used on that JSON (we accepted a 10% increase in size for a 50% decrease in compute).
Saving QuantumGraph objects (primarily that transformation to JSON, which also involves normalizing a lot of data structures to avoid duplication) is now clearly the dominant contributor to the time spent in QG generation, and while we do have some ideas for how to improve that further, they may require some deep changes to the in-memory QuantumGraph class and/or its file format, and probably aren’t right around the corner.