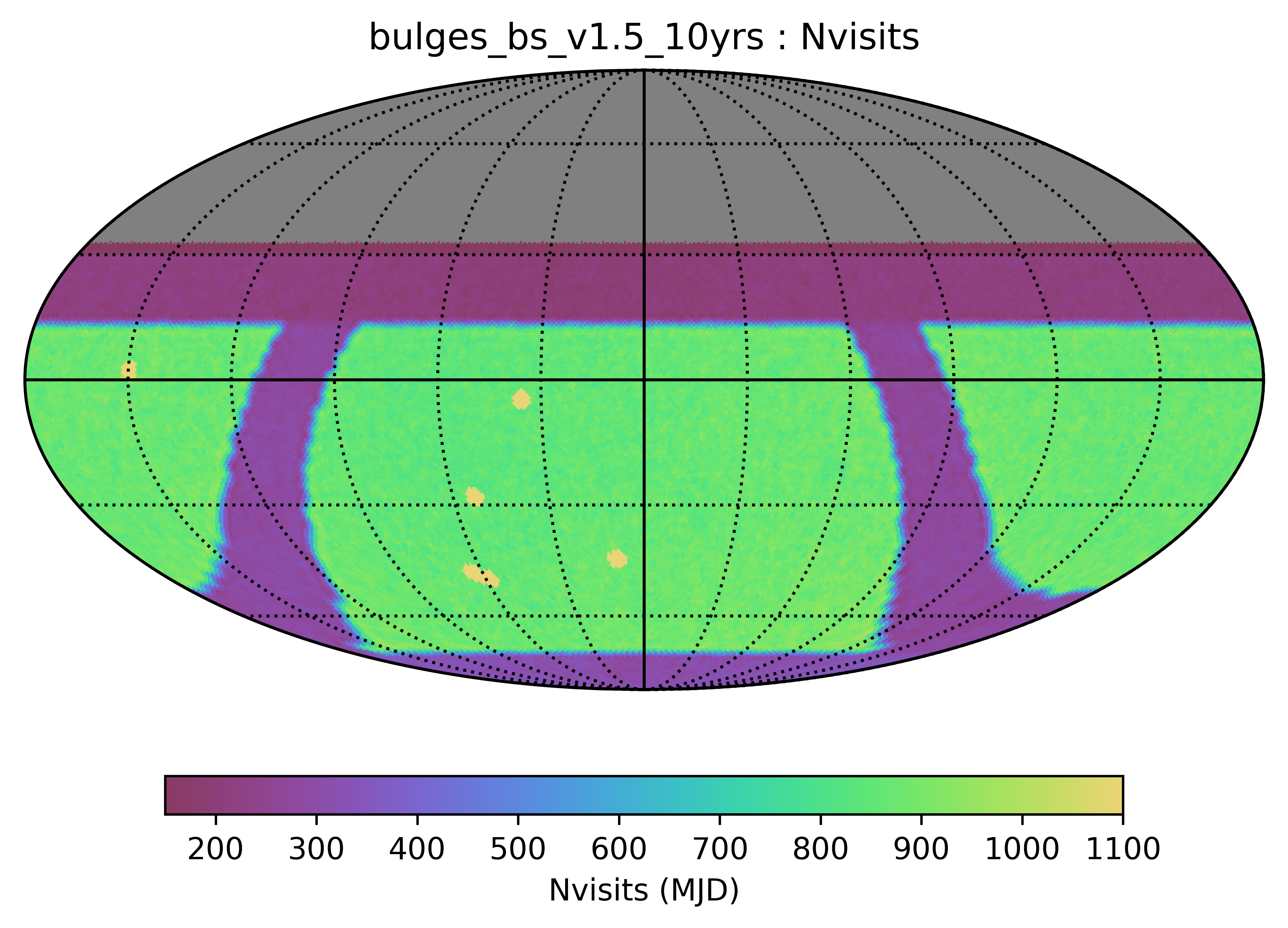
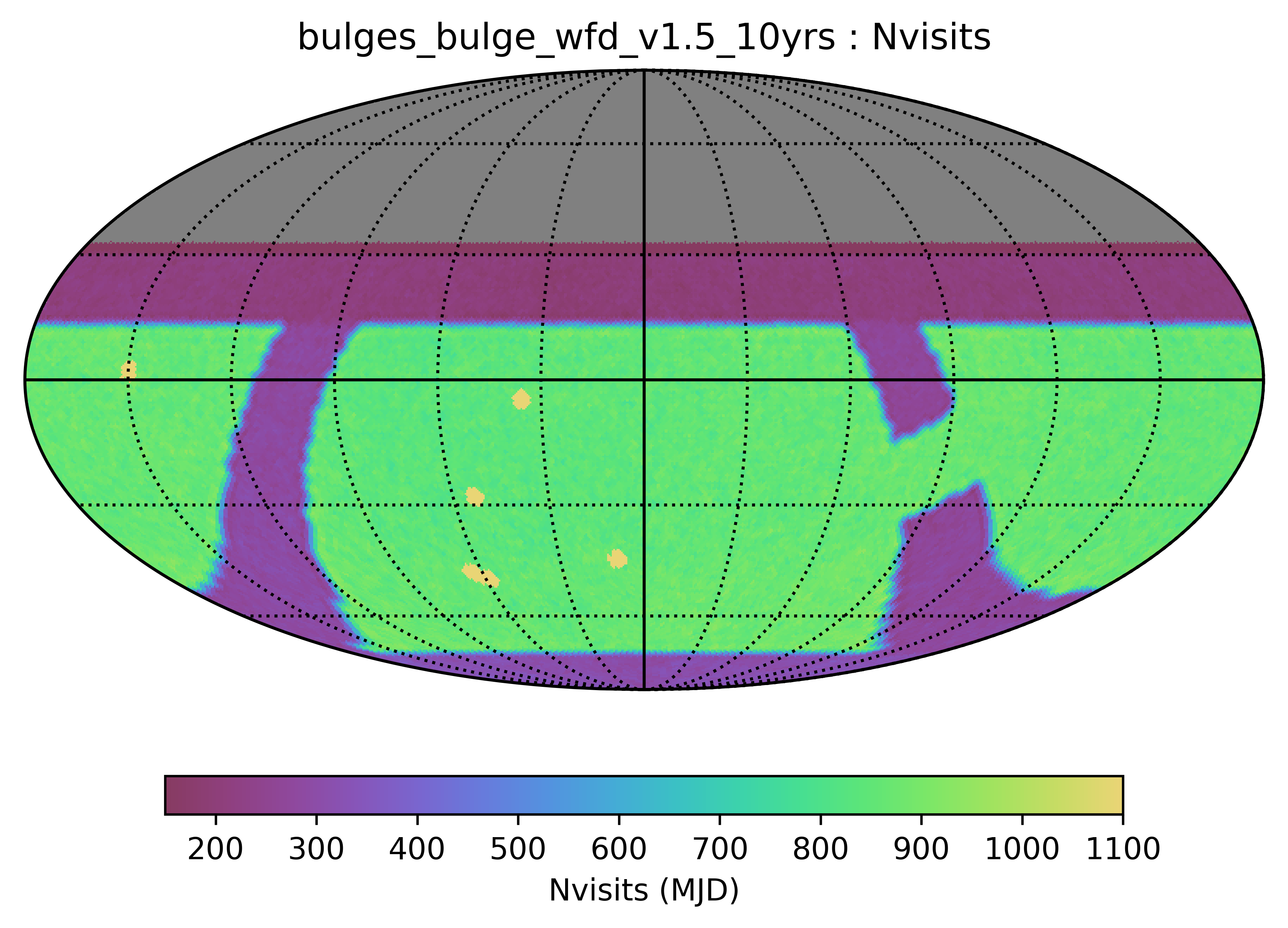
Some thoughts and metrics related to the survey strategy and solar system science.
Context: general solar system science metrics include discovery metrics (with various discovery criteria) and characterization metrics (ie. how many colors for objects can we measure, and can we determine a light curve or even shape measurement from the lightcurve). The most important metric is discovery; if we can’t find the objects, then we can’t do anything else with them (or follow them up at other observatories). Secondary metrics are all of the characterization metrics. There are multiple populations of small bodies throughout the solar system, which move with different apparent velocities and cover varying amount of the sky (generally centered on the ecliptic, but some more widely distributed than others).
As such, survey strategy can have different effects on different populations, even when considering just one metric. Secondary metrics can also be important, especially if the primary discovery metric isn’t a strong differentiator between strategies.
With that, we can look at various aspects of the survey strategy.
First up - intranight strategy
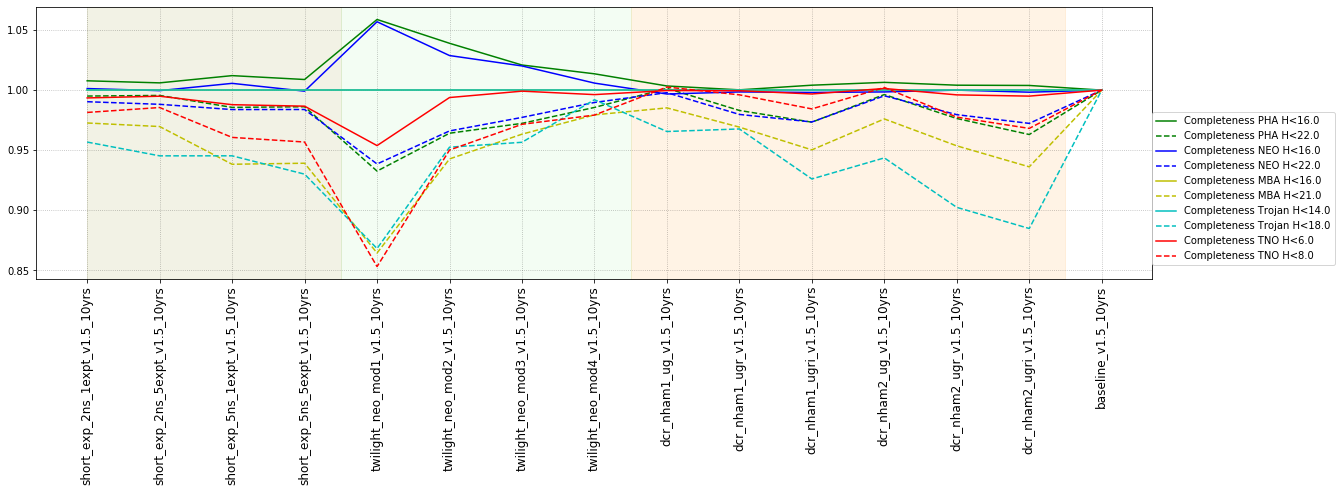
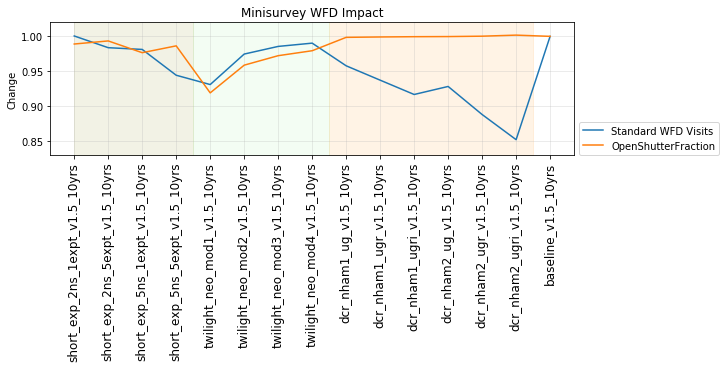
The relevant simulations here include visits = 2x15s snaps or visits = 1x30s snap, whether we have single visits per night, double visits, or triples (for some fraction of each night).
The relevant simulations (due to an oversight on the project side) include runs from FBS 1.4 and FBS 1.5 … the metric outputs for each run are normalized by the relevant baseline_vX_10yrs output.
The list of runs included for consideration are:
['nopairs_v1.4_10yrs',
'baseline_2snaps_v1.5_10yrs',
'baseline_v1.5_10yrs',
'baseline_v1.4_10yrs',
'baseline_samefilt_v1.5_10yrs',
'third_obs_pt15v1.5_10yrs',
'third_obs_pt30v1.5_10yrs',
'third_obs_pt45v1.5_10yrs',
'third_obs_pt60v1.5_10yrs',
'third_obs_pt90v1.5_10yrs',
'third_obs_pt120v1.5_10yrs']
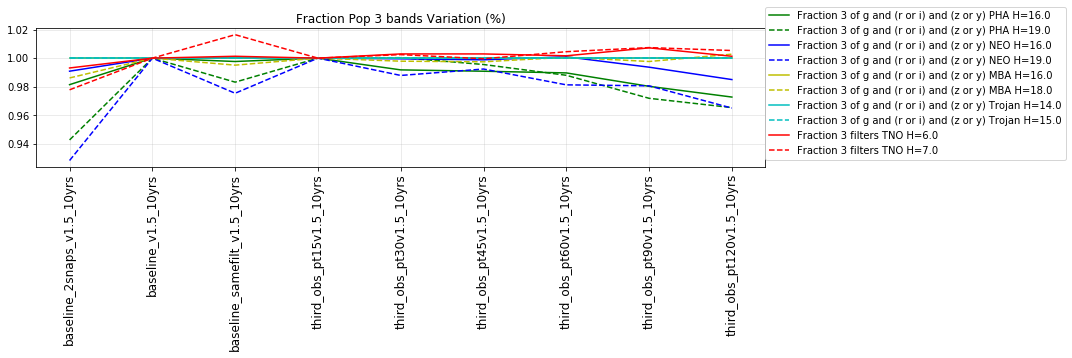
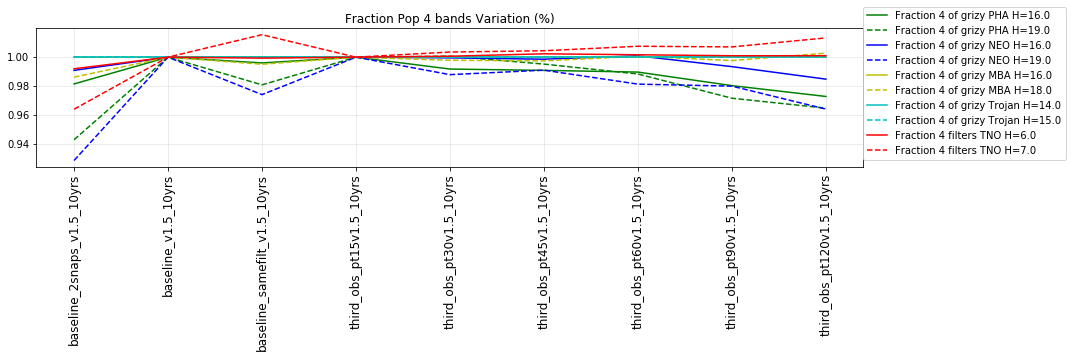
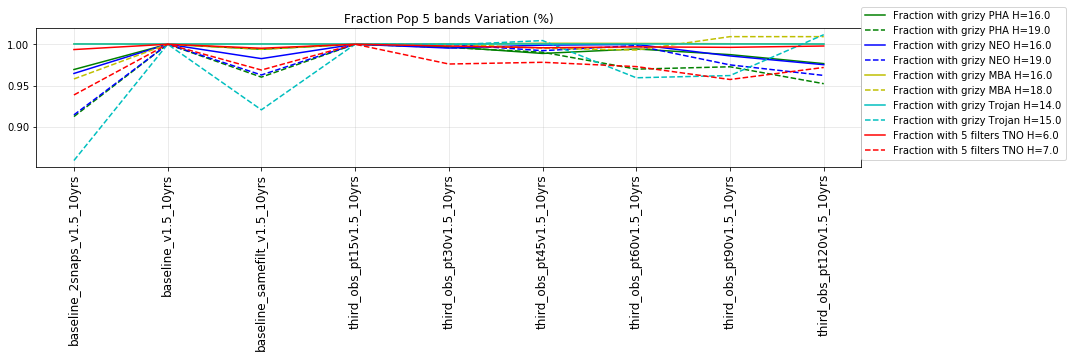
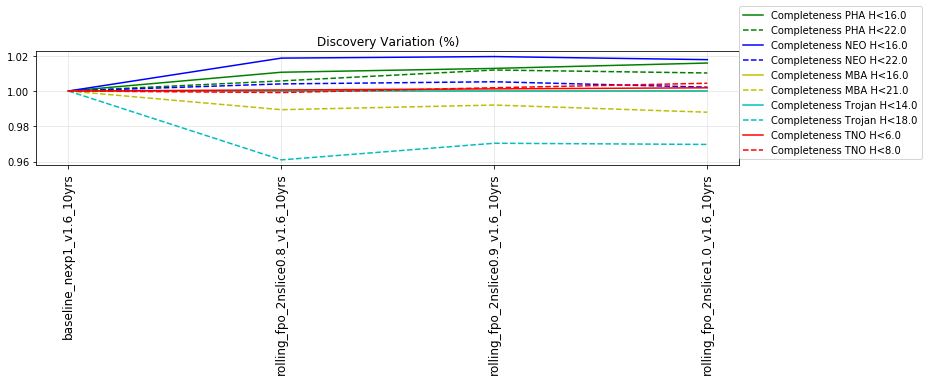
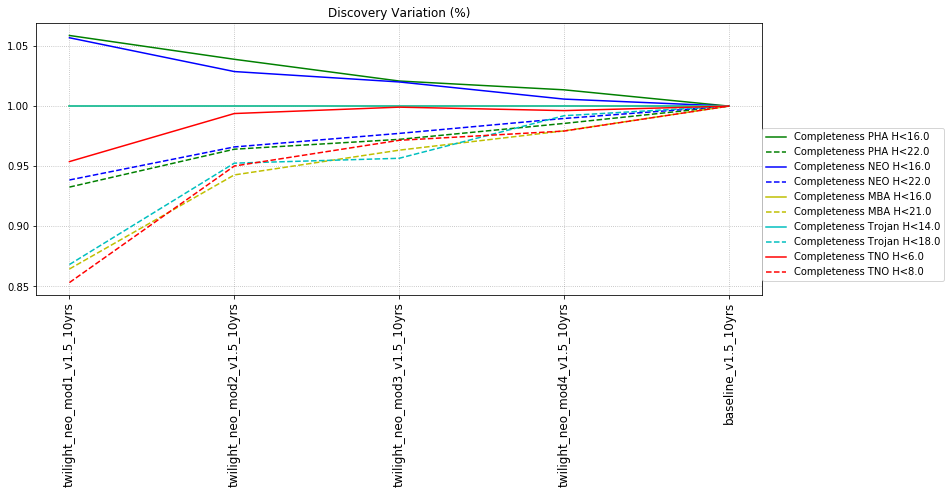
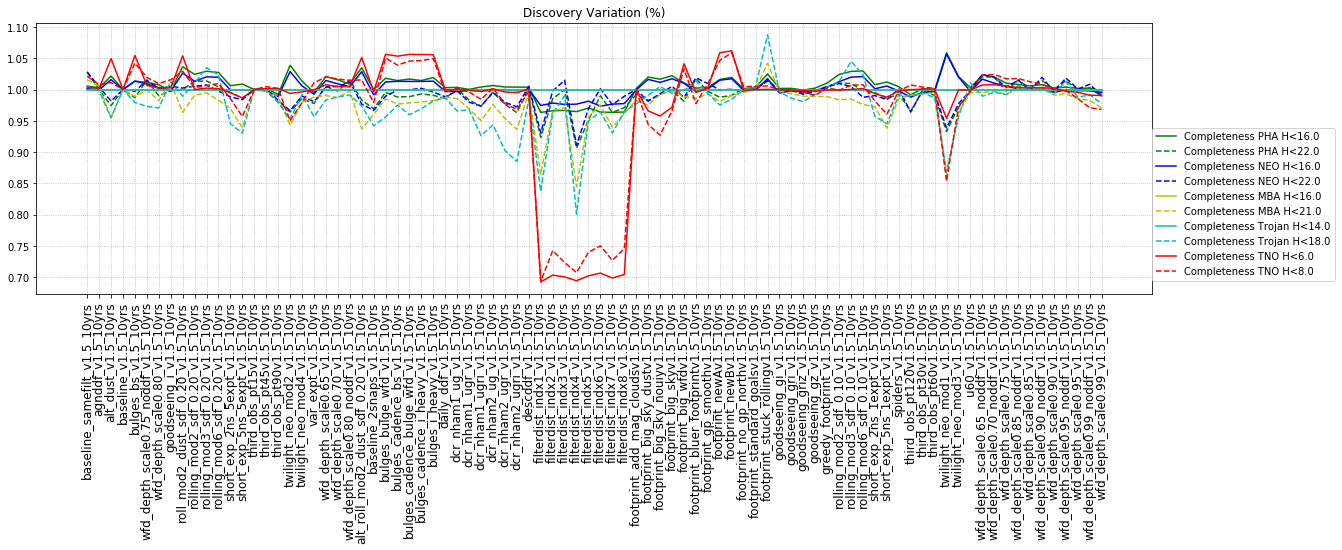
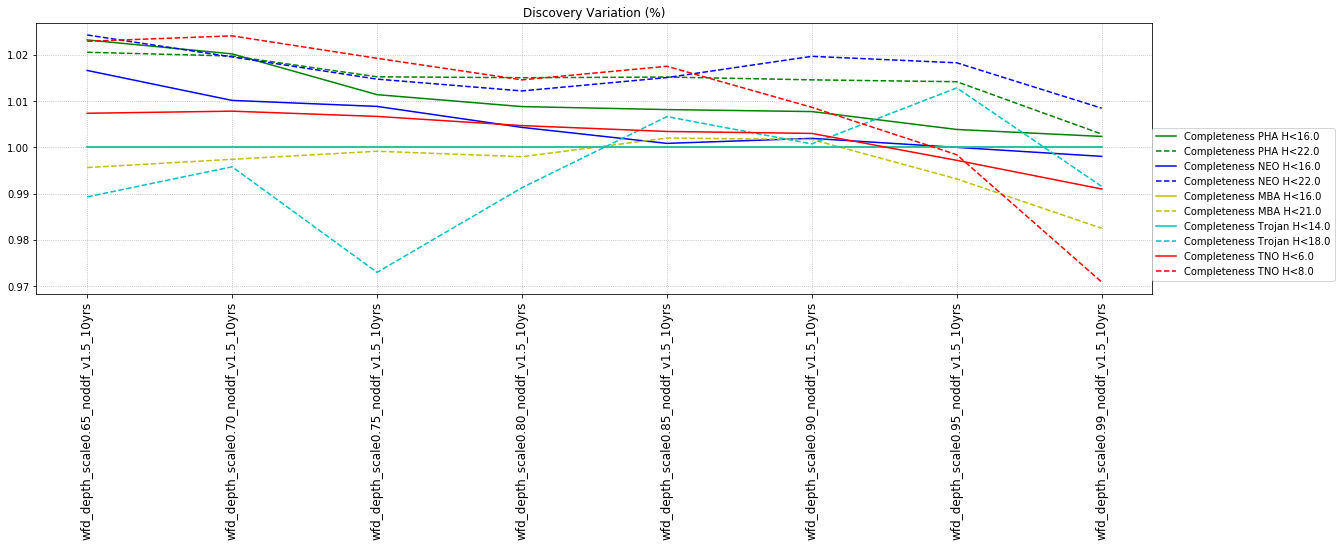
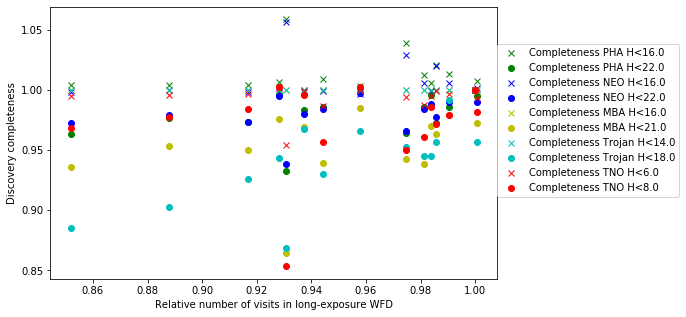
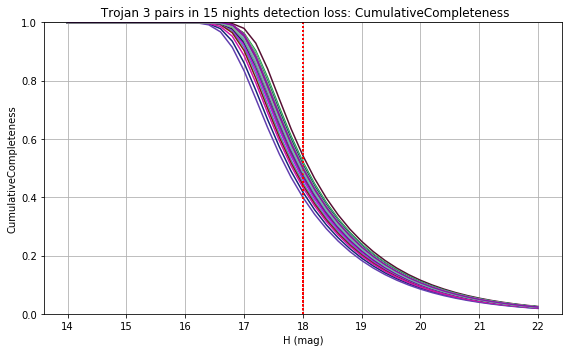
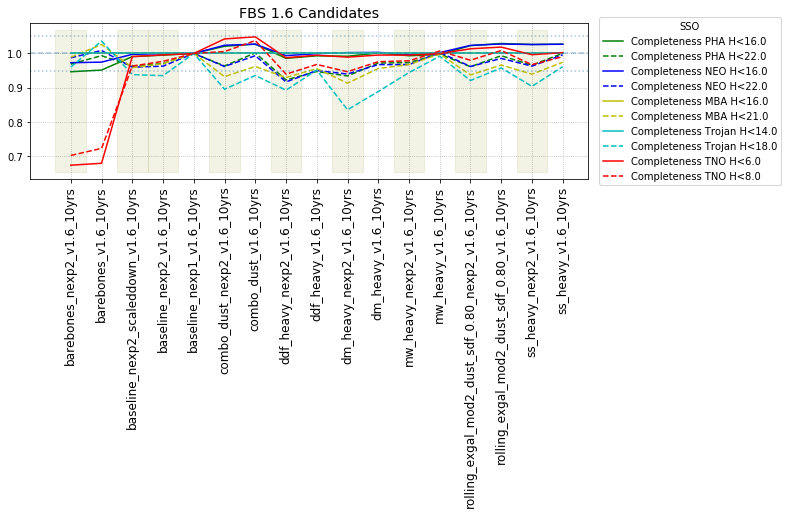
The punchline is the following plot, showing the discovery completeness at bright and 50% values, for various populations, across all of these runs.
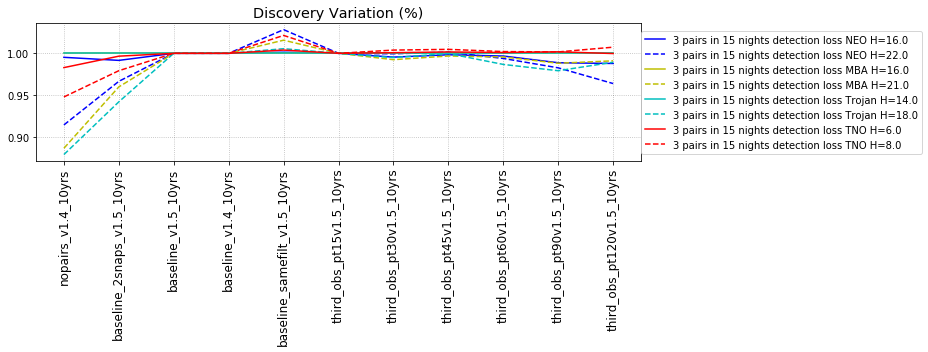
It may be surprising that the ‘no pairs’ simulation results in any objects being found at all - that we do find any means that fields have not-insignificant overlaps within a night, that sometimes objects move between fields, and that sometimes we take pairs of visits in a night anyway.
This can be seen in the intranight histogram as well … no pairs and standard baseline histograms below, which show that the number of repeat visits within a night drops significantly for the no-pairs simulation, but not to 0.
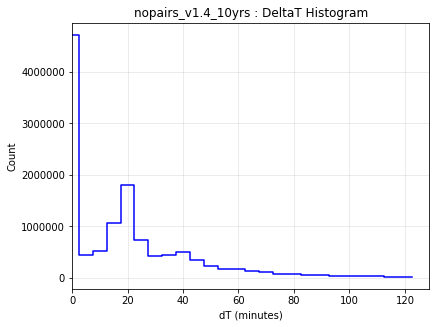
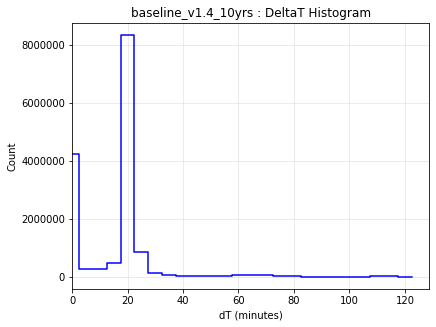
It should be noted that the existence of overlaps of visits in the ‘no-pairs’ state is fragile … if the scheduler algorithm was changed to reduce overlaps, then these would likely disappear.
This shows that the favored strategy would be taking pairs of visits, in the same filter within the night (about a 3% improvement in the discovery fraction of NEO and PHAs). Strongly disfavored strategies would be single visits per night (an over 10% hit for main belt asteroids), due to the requirement of two observations per night for MOPS linking. The 2x15s strategy (2snaps) vs. 1s30s strategy (1snap per visit) involves about a 5% decrease in completeness for Trojan asteroids, with varying decreases among other populations – this is generally linked to the overall fewer number of visits possible when doing 2snaps vs. 1. Observing with a triple visit near the end of the night is not a significant issue until the amount of time devoted to triples is large (the pt90 and pt120 runs), at which point it can result in about 4% fewer NEOs being discovered. This is most likely due to the decreased amount of sky observed in each night.
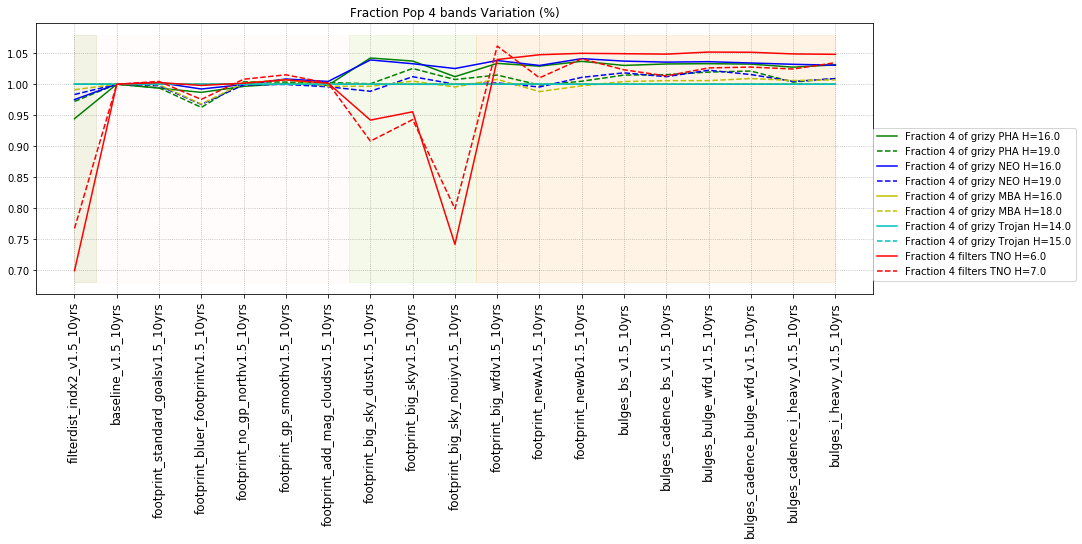
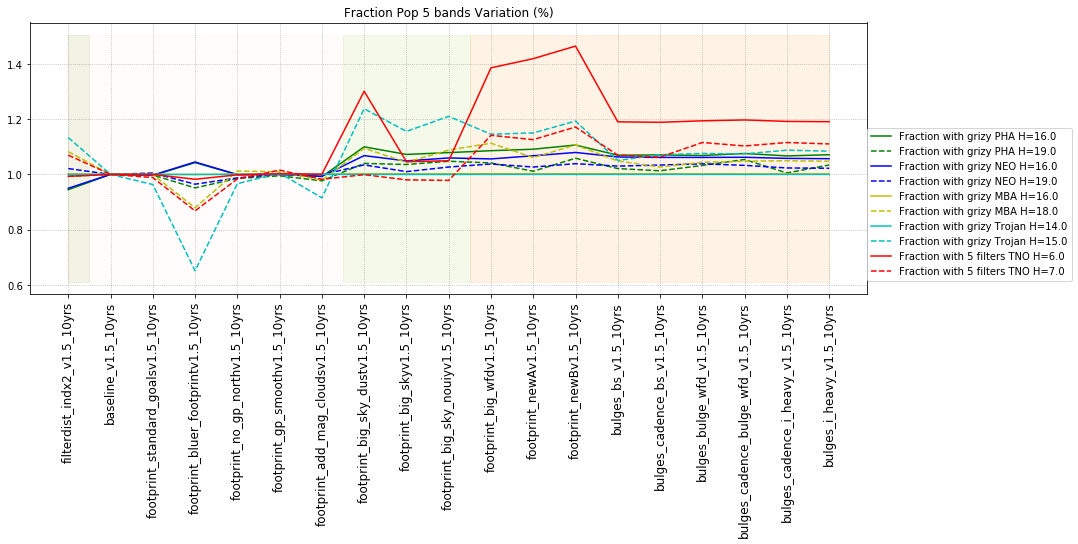
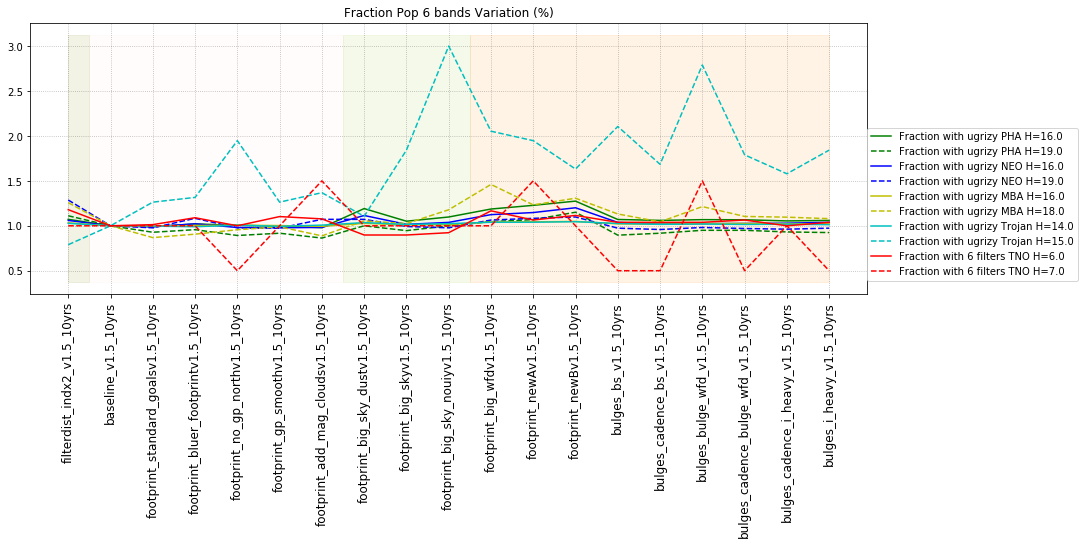
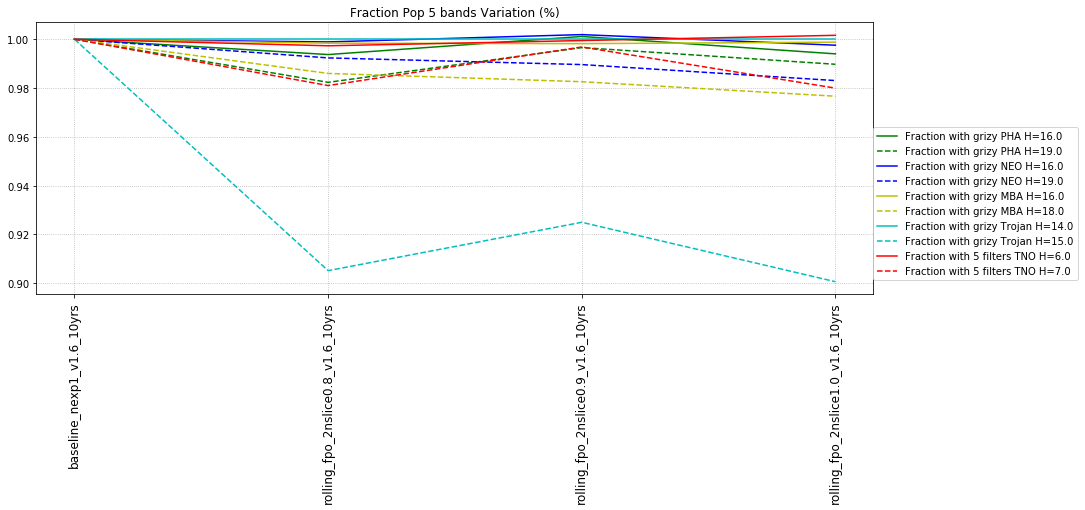
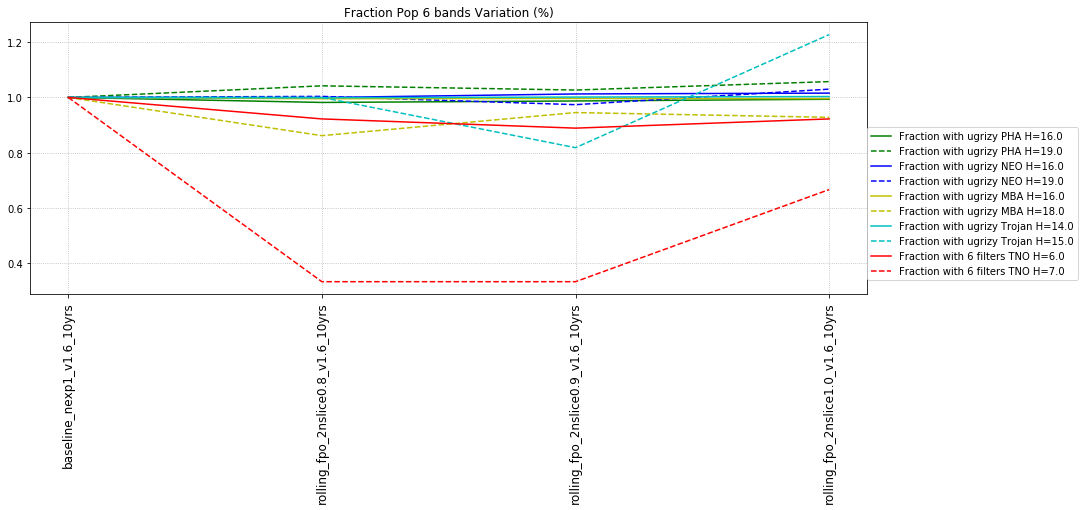
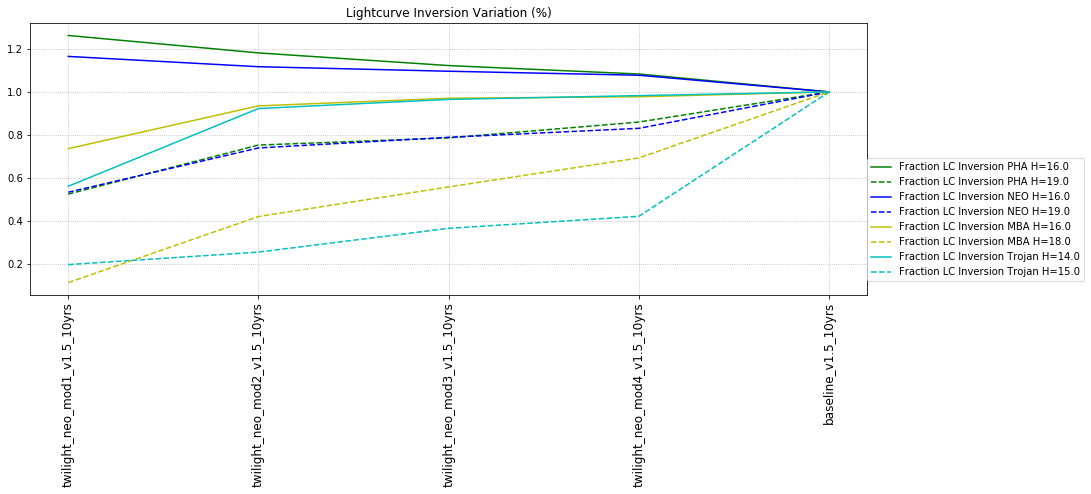
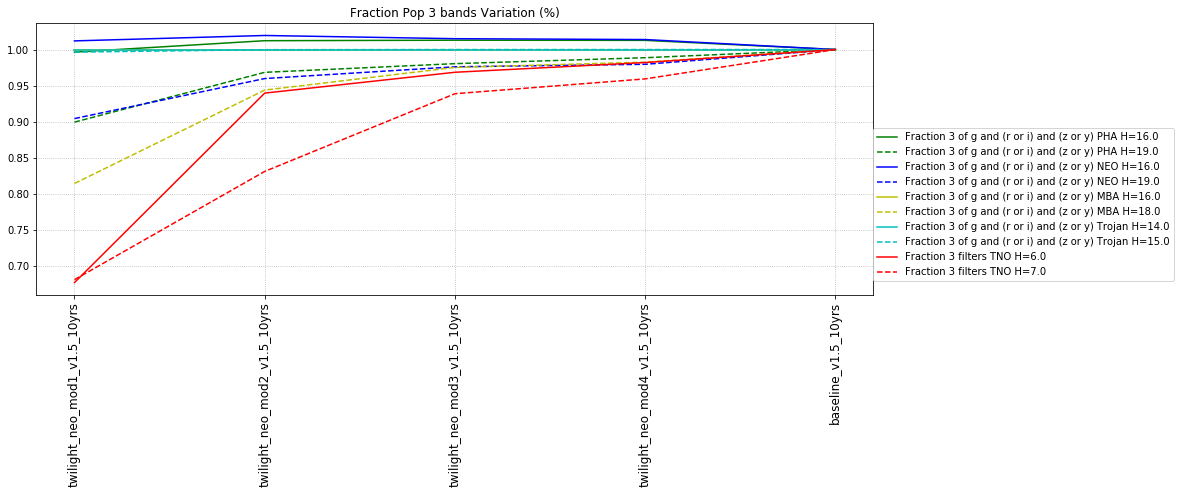
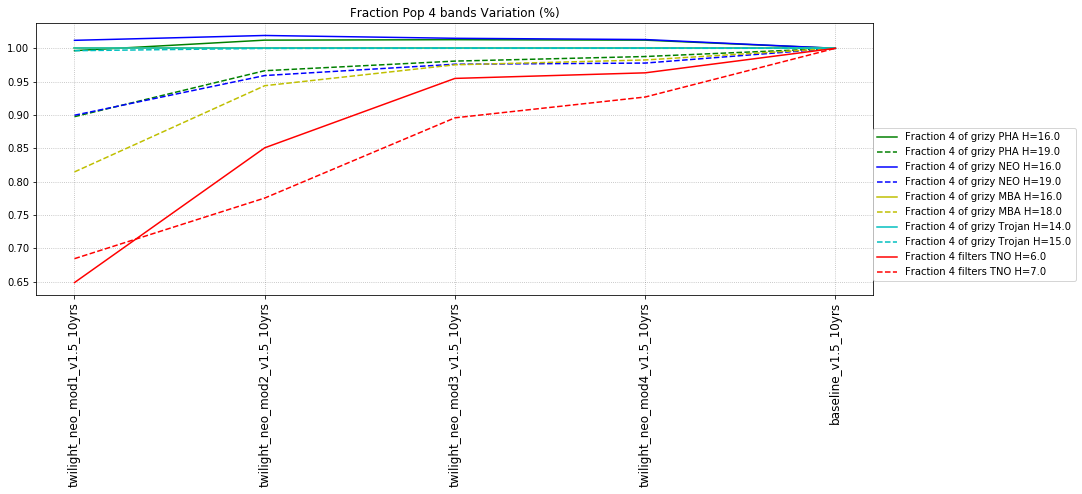
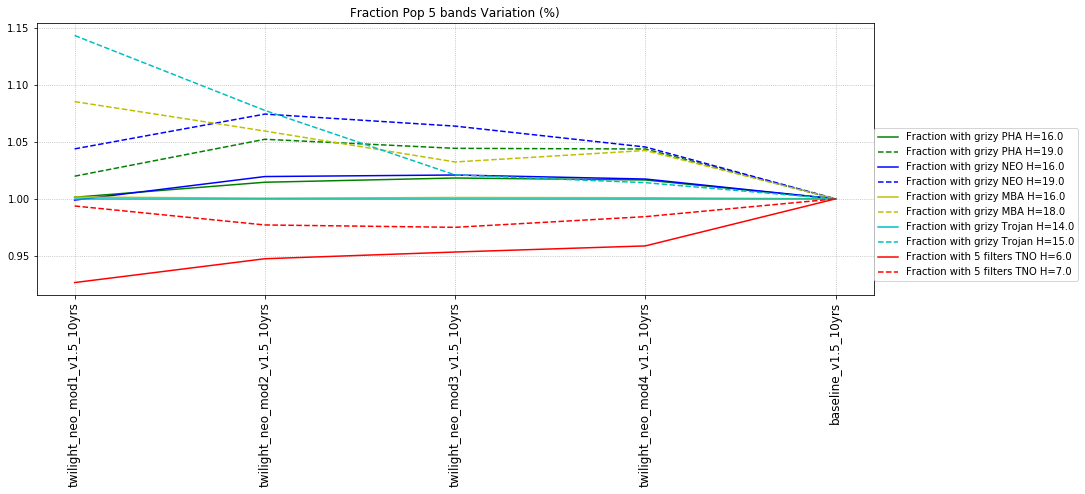
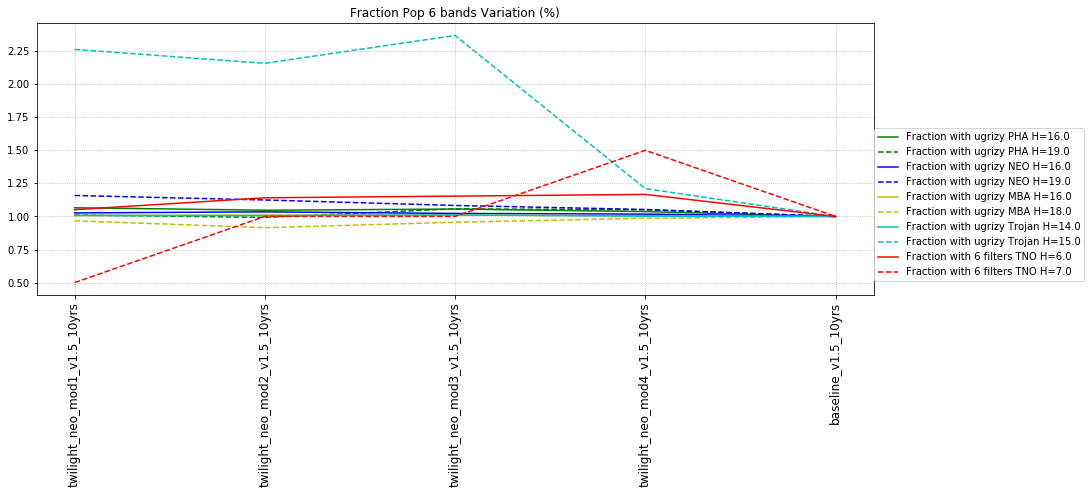
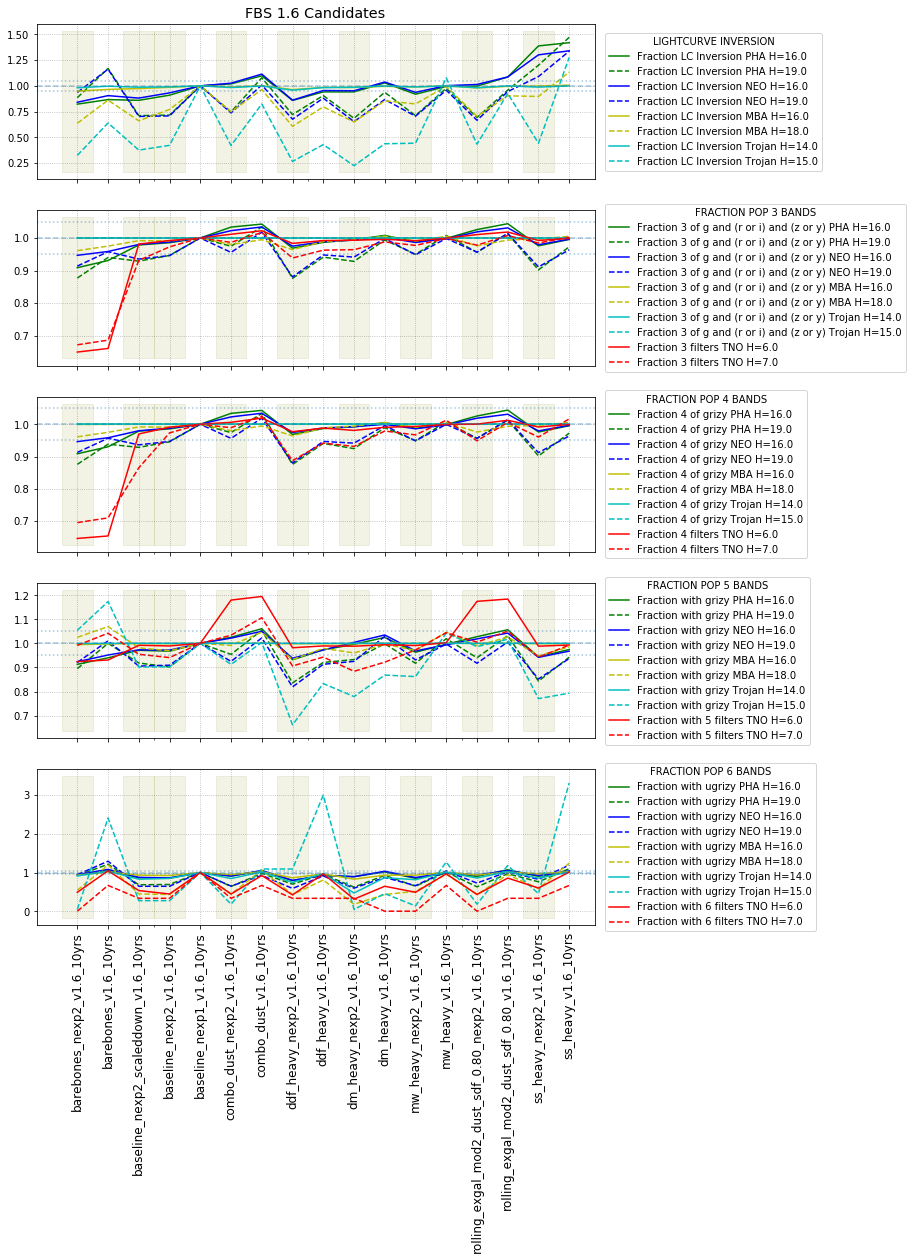
It’s worth noting that observing each pair in the same filter, while it has a benefit for discovery, has a small cost for characterization, at least when looking at the number of objects which can be measured in 4 colors (primarily for Jovian Trojans). Here are the characterization metrics: there is a difference between outer solar system (TNO) and inner solar system (PHA, NEO, MBA, Trojan) metrics here.
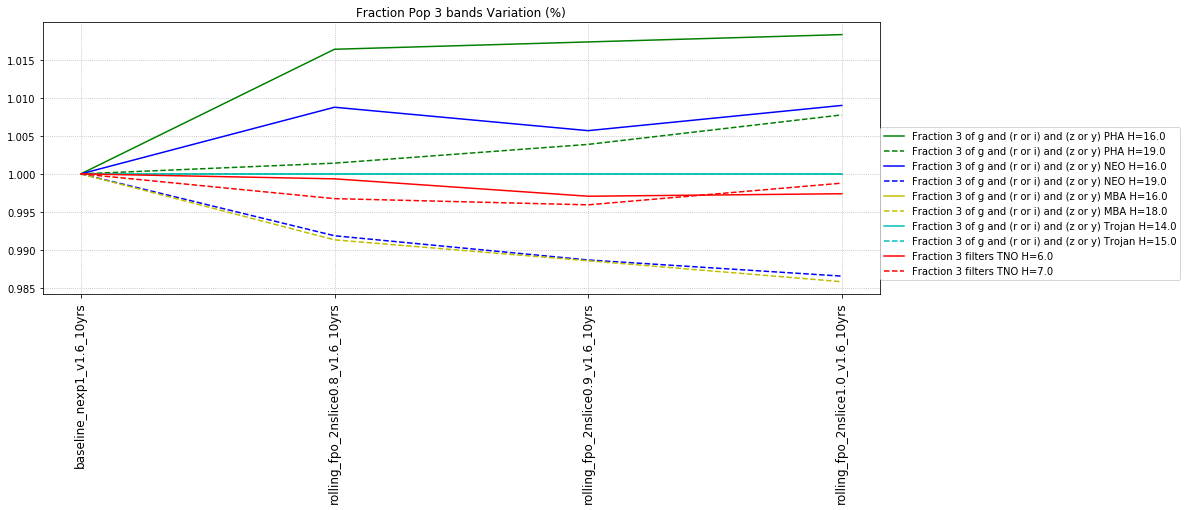
Inner solar system metrics for colors look specifically for the fraction of the population with:
- Three of either g and (r or i) and (z or y) – i.e. obtain 2 colors g-r or g-i PLUS g-z or g-y
- Any 4 different filters (from grizy). i.e. 3 colors = g-r, r-i, i-z, OR r-i, i-z, z-y.
- All 5 from grizy. i.e. 4 colors = g-r, r-i, i-z, z-y.
- All 6 filters (ugrizy) – best possible! add u-g color
To decide if a filter is ‘acceptable for color determination’, the metric calculates the sum of a snr-weighted number of visits and compares that to a threshold value. For example, in the standard configuration, either 41 visits with a snr of 5 OR 11 visits with a SNR of 20 would need to be acquired to count as a detection in a single band (SNR values higher than 20 still require at least 11 visits).
Outer solar system metrics for colors look for the fraction of the population with:
- enough visits in a single band for a lightcurve (default 30 visits) (1 band)
- enough visits in a primary band for a lightcurve, plus additional visits (default 20) in another band to measure a color (2 bands = 1 color)
- additional visits (20) in additional bands for more colors (3 bands = 2 colors, etc.)
So, less specific colors and a slightly different way to count towards a color.
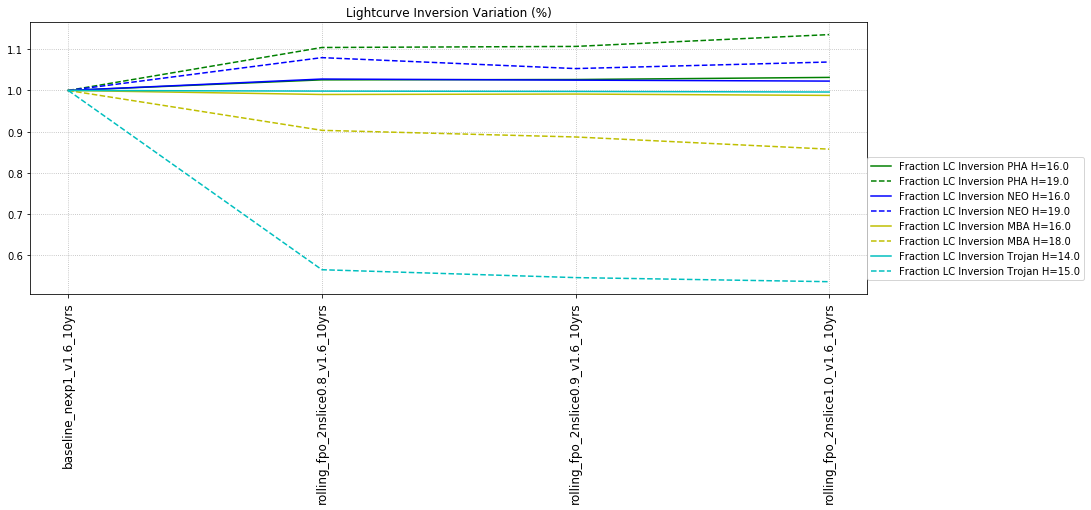
The inner solar system also has an additional metric for lightcurve inversion. This metric likewise looks for a certain number of SNR-weighted observations (the default would be equivalent to 1000 observations at SNR of 5 or 50 at SNR of 100 or 250 at SNR of 20). It then adds more requirements on the phase angles of the observations – the phase coverage must be more than 5 degrees, the range of ecliptic longitudes has to be more than 90 degrees, and the absolute deviation of the ecliptic longitude coverage has to be more than 1/8 of the coverage range.